
Aug 16, 2020 Tags: devblog, programming, rust, x86
This post is at least a year old.
This is a quick writeup of a steganographic tool that I threw together: steg86. It uses a quirk of the x86 instruction encoding format to hide messages in pre-existing binaries with no size or performance overhead.
You can play with it yourself by fetching it with cargo:
1
2
$ cargo install steg86
$ steg86 --help
Steganography is the practice of concealing data within other data. A variety of different common formats open themselves up to steganographic channels:
On its own, steganography is not a replacement for cryptography: it’s strictly obfuscatory, and does not provide any deniablity of the embedded message if revealed.
That being said, there exist a variety of use cases for steganographic schemes:
There are two obvious avenues for doing steganography on compiled programs. steg86 does neither of these, but for the sake of completeness:
Compilers perform instruction selection to lower their internal representations into machine code. Instruction selection can be informed by any number of weights, including register pressure, individual instruction performance (clock cycles, use of shared units), and feature availability (e.g., selecting an older version of SSE to be compatible with more CPUs).
In this approach, the steganographer would control the compiler and its instruction selection weights, encoding information in particular selections of instructions (or other parts of code generation, like stack object order).
This affords a great deal of flexibility and control, but also makes it more difficult for the compiler to perform optimal selections. It also requires the steganographer to maintain their (forked) compiler. Not a bad idea, but requires a decent amount of effort.
Another approach is to ignore the compiled instructions themselves, and focus on the binary container: ELF, Mach-O, or PE, among others.
These formats afford many opportunities for embedding information: the order (both file and virtual address) of segments and sections, the order and layout of relocation tables and the composition of their internal rules, and so on.
Instrumenting the binary format rather than the executable code means not having to muck with instruction selection, but is also less bountiful in terms of information density. It’s also not portable, e.g. tricks for hiding information in ELF relocation entries would have to be tweaked for PEs.
Instead of controlling instruction selection or tweaking the details of the containing binary format, steg86 takes a third route: it uses the presence of semantic duals in the x86 and AMD64 instruction formats to selectively rewrite a program after compilation.
Like every ISA, x86 (and AMD64) have multiple ways to encode the semantics of a particular (higher level, conceptual) operation. For example, clearing a register:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
; xor'ing a register with itself clears all bits
xor eax, eax
; and'ing a register with 0 also clears all bits
and eax, 0
; we could also set 0
mov eax, 0
; ...or subtract
sub eax, eax
; ...or load a "computed" address that's always 0
lea eax, [0]
…among many others. Unfortunately, this doesn’t work exactly as we’d like:
xor eax, eax versus 6 for lea eax, [0]. Consequently, rewriting one in terms of another
might entail a length change and subsequent relocation and displacement fixups.Fortunately, this is not what steg86 does.
Instead, steg86 takes advantage of one of the quirks of the x86 instruction encoding: the ModR/M byte:
The ModR/M byte is normally used to encode one or more explicit register and/or memory operands to an opcode1: it’s how x86 can supply the rich range of source-to-sink modes that it has (register-to-memory, memory-to-register, register-to-register, immediate-to-register, &c).
Because register-to-memory and memory-to-register are both valid source-sink combinations for many opcodes, many have encoding forms like the following:
1
2
3
4
5
; xor register with register/memory32 and store register/memory32
xor r/m32, r32
; xor register/memory32 with register and store register
xor r32, r/m32
Consequently, there are actually two ways to encode xor eax, eax:
1
2
3
4
5
; r/m32, r
31 C0
; r, r/m32
33 C0
These encodings are semantic duals: they have different opcodes, but belong to the same
instruction family, have the same length, and have the exact same behavior and performance.
We could replace every occurrence of 31 C0 with 33 C0 and our programs would happily chug along,
none the wiser.
As it turns out, there are actually quite a few of these duals on some of the most common x86 instructions2:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
ADD r/m8, r8 <=> ADD r8, r/m8
ADD r/m16, r16 <=> ADD r16, r/m16
ADD r/m32, r32 <=> ADD r32, r/m32
ADD r/m64, r64 <=> ADD r64, r/m64
ADC r/m8, r8 <=> ADC r8, r/m8
ADC r/m16, r16 <=> ADC r16, r/m16
ADC r/m32, r32 <=> ADC r32, r/m32
ADC r/m64, r64 <=> ADC r64, r/m64
AND r/m8, r8 <=> AND r8, r/m8
AND r/m16, r16 <=> AND r16, r/m16
AND r/m32, r32 <=> AND r32, r/m32
AND r/m64, r64 <=> AND r64, r/m64
OR r/m8, r8 <=> OR r8, r/m8
OR r/m16, r16 <=> OR r16, r/m16
OR r/m32, r32 <=> OR r32, r/m32
OR r/m64, r64 <=> OR r64, r/m64
XOR r/m8, r8 <=> XOR r8, r/m8
XOR r/m16, r16 <=> XOR r16, r/m16
XOR r/m32, r32 <=> XOR r32, r/m32
XOR r/m64, r64 <=> XOR r64, r/m64
SUB r/m8, r8 <=> SUB r8, r/m8
SUB r/m16, r16 <=> SUB r16, r/m16
SUB r/m32, r32 <=> SUB r32, r/m32
SUB r/m64, r64 <=> SUB r64, r/m64
SBB r/m8, r8 <=> SBB r8, r/m8
SBB r/m16, r16 <=> SBB r16, r/m16
SBB r/m32, r32 <=> SBB r32, r/m32
SBB r/m64, r64 <=> SBB r64, r/m64
MOV r/m8, r8 <=> MOV r8, r/m8
MOV r/m16, r16 <=> MOV r16, r/m16
MOV r/m32, r32 <=> MOV r32, r/m32
MOV r/m64, r64 <=> MOV r64, r/m64
CMP r/m8, r8 <=> CMP r8, r/m8
CMP r/m16, r16 <=> CMP r16, r/m16
CMP r/m32, r32 <=> CMP r32, r/m32
CMP r/m64, r64 <=> CMP r64, r/m64
Each dual represents one bit of information: we can arbitrarily assign one form
to be true and its counterpart to be false. Given enough of them in a target
program, we can hide a message by translating between the forms. The result:
a binary that’s exactly the same size as the original and with the same performance
characteristics, but with a hidden message.
That’s all steg86 does: it locates every semantic dual in its target program, maps
its input message to a bitstring, and translates each dual depending on its corresponding
message bit. Because it only uses duals, it’s completely agnostic to its containing format:
the steg86 CLI currently supports ELF, Mach-O, and PE/PE32+ binaries.
Here’s what that actually looks like, with (some of the) differing bytes highlighted in red:
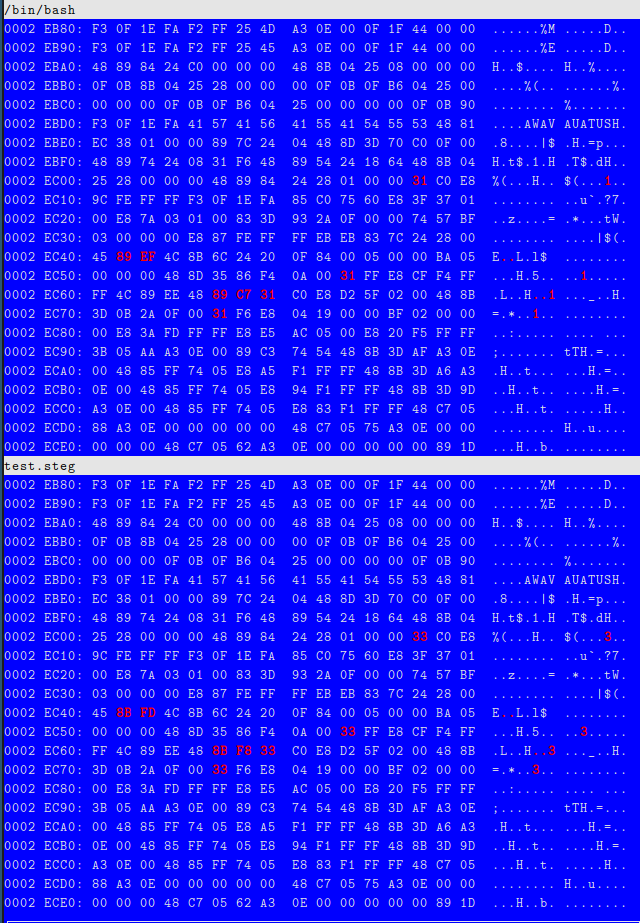
And, of course, try it for yourself:
1
2
3
4
5
6
7
8
9
10
11
12
$ steg86 profile /bin/bash
Summary for /bin/bash:
175828 total instructions
27957 potential semantic pairs
27925 bits of information capacity (3490 bytes, approx. 3KB)
$ steg86 embed /bin/bash test.steg <<< "hello world!"
$ file test.steg
test.steg: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=a6cb40078351e05121d46daa768e271846d5cc54, for GNU/Linux 3.2.0, stripped
$ steg86 extract test.steg
hello world!
See the README for prior work and future refinements to steg86’s informational capacity.
Edit: An important note: because compilers and assemblers tend to select just one of the forms above, steg86 cannot provide deniability, even with strong encryption. Its transformations will always look abnormal compared to a compiler-produced binary.