ENOSUCHBLOG
Programming, philosophy, pedaling.
Aug 20, 2022
Tags:
curiosity,
programming
This post is at least a year old.
This is a summary of a random thought I had on the subway.
Just about everybody who has ever used a service on the web has experienced the
following account creation follow:
- Click “New account”,
- Enter a username and/or email and password,
- Log in, only to discover that the account is locked or limited pending “email verification.”
“Email verification,” in turn, means:
- Opening up a new browser tab or clicking on your email client,
- Waiting for an email to appear from the service,
- Finding the right “verification” URL in the email and clicking it,
- Being redirected to a splash page affirming that your email has been
verified, and your account is fully usable.
In my experience, just about every step in the second list can fail in user-hostile
ways:
-
I’ve repeatedly dealt with services where the verification email takes minutes to arrive,
is marked as spam, or simply never arrives at all. Sometimes clicking the “resend
email” works and triggers a deluge of N verification emails at once, leaving me
unsure which one to click.
Depending on the service, clicking on a stale verification link may or may not
work, may or may not be a no-op (with or without an explanatory error), and may or may
flag your account as suspicious (for performing an authenticated action that has been flagged
as stale, due to clicking “resend”).
Takeaway: Inbox delivery can be fickle, unreliable, or outright impossible.
When users don’t receive a verification email immediately, they feel stuck.
-
Lots of verification emails are HTML formatted, which makes them (generally)
look great in browser- and other HTML-friendly email clients. For example,
here’s how Etsy’s verification email looks in GMail:
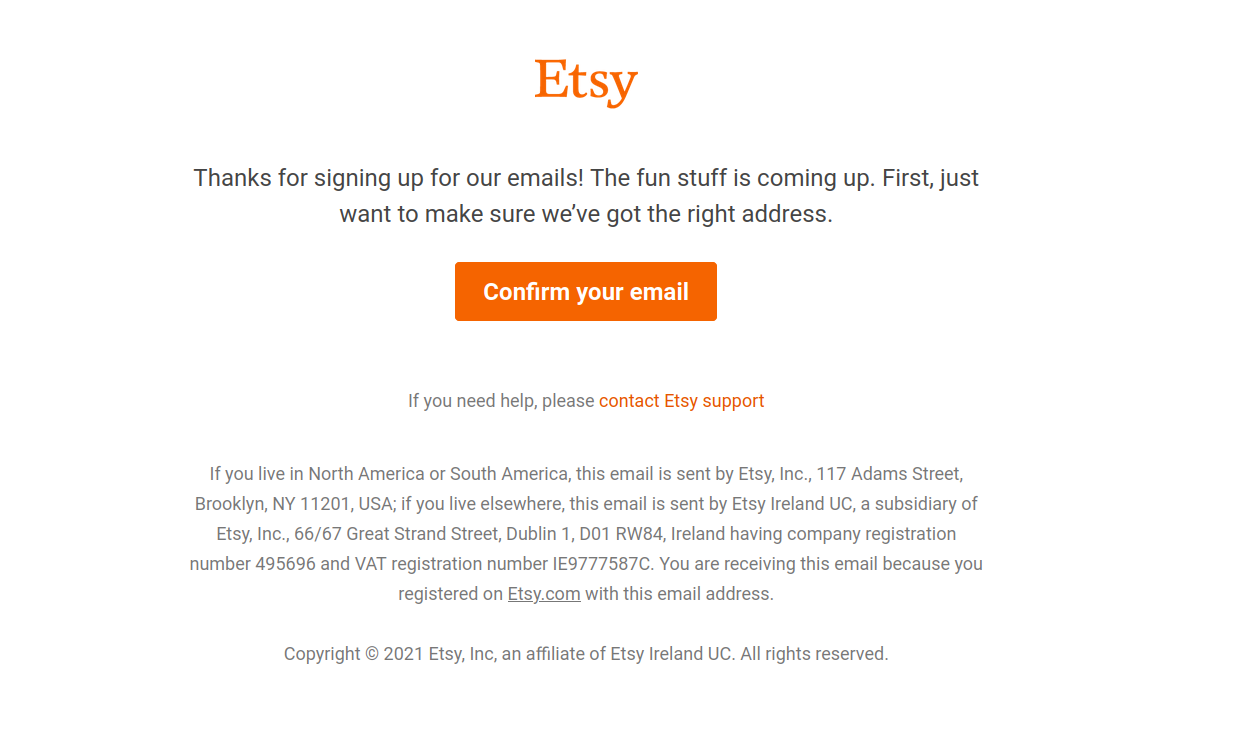
Not bad at all! It’s very easy to see which link to click for the “happy path.”
…and here it is in neomutt, which helpfully “renders” the HTML with lynx:
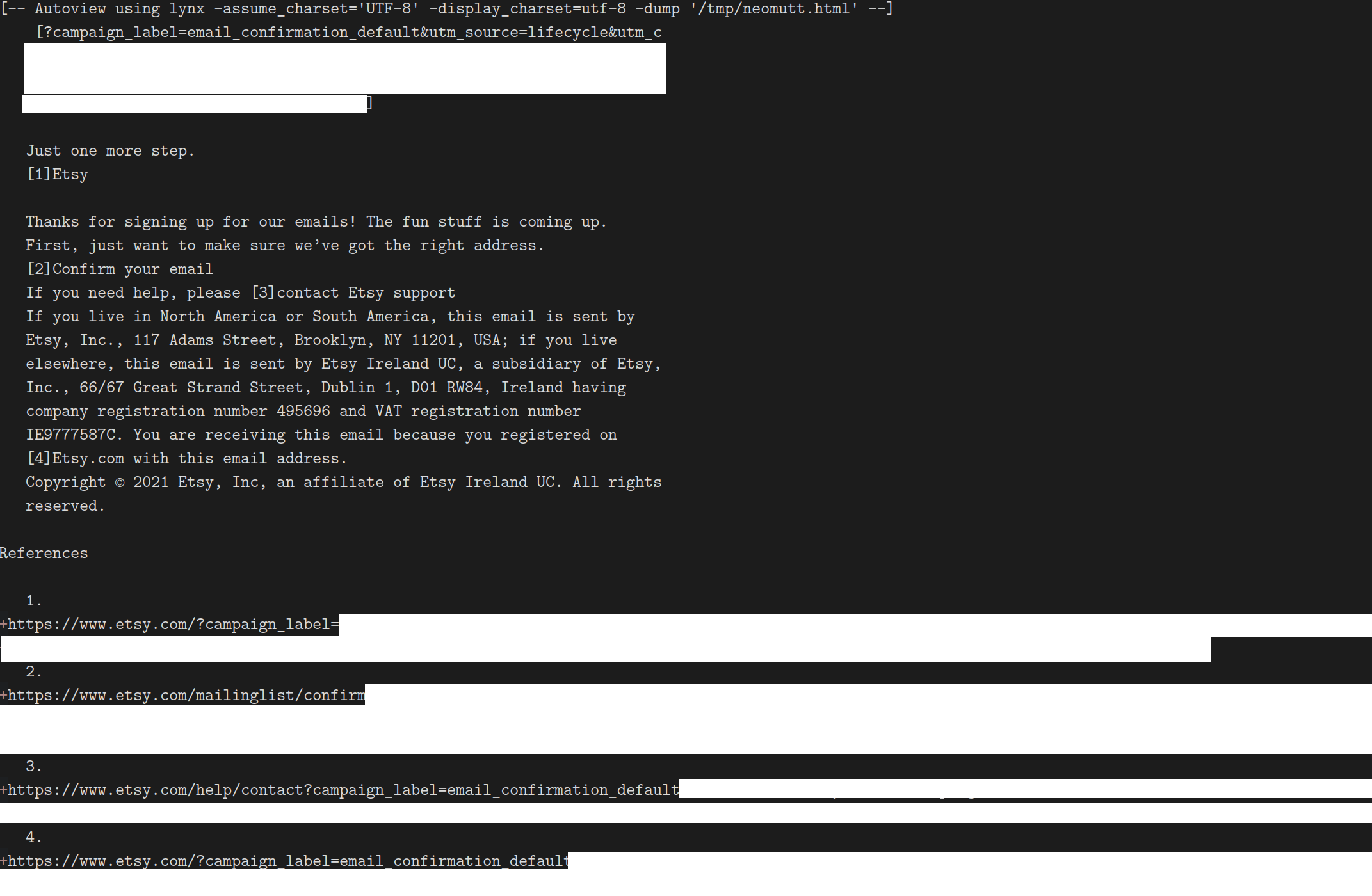
I’m used to visually scanning these emails at this point, so I can pick out the right link
(it’s [2]) and bring it into my browser. But that’s a solution born from practice: the
fact remains that HTML email doesn’t generally degrade gracefully in clients that don’t
support images or CSS.
Naturally, developers do consider these kinds of edge cases, and frequently include a plaintext
alternative. Etsy’s is very nice:

…but not always: I’ve received plenty of verification emails with only HTML components,
leaving me to visually scan the body and pick the right URL out. I can’t count the number
of times I’ve picked the wrong URL or accidentally truncated it.
Takeaway: HTML verification emails are pretty and serve the average user well,
but degrade poorly and complicate verification for non-paradigmatic users.
Plaintext alternatives are the solution, but support is spotty.
-
In general, clicking on the verification link does what I expect: it opens a new tab in
my browser, telling me that I’ve been verified. Sometimes it’s even a splash, showing me
that I’m verified and that my active browser session has been “promoted” to an ordinary
user session.
But this too has plenty of failure modes:
-
I often have multiple browser sessions open: one for work, one for personal accounts
or music streaming, &c. When I click the link, my browser chooses the “most recent”
browser session as the link recipient, which is frequently wrong. Sometimes this works (when
the verification link itself contains sufficient state to link the click), but frequently it
doesn’t: the verification barfs when the browser doesn’t have the right cookies for
the account being verified.
-
When I do get the right browser session, all appears peachy: I’m told that I’m
verified, and can go about the ordinary activities of the account I’ve signed up for.
Except not: I regularly have to log out and back in again, since the browser’s login
session hasn’t been updated to match the verification status. This is admittedly
an extremely small inconvenience, but it’s an inconvenience and unnecessary
failure mode nonetheless.
Takeaway: The redirection back to the browser is flimsy, and reveals
error states (such as session mismatches) that shouldn’t be possible.
All in all, I would describe the “normal” email verification flow as Kafkaesque:
ambiguity and anxiety come in the forms of both time and space; unwritten rules
must be followed and may or may not result in stated outcomes; I am considered a
suspect (“unverified account”) until I have completed obscure and performative rituals.
So, the thought I had: why not do email verification “in reverse”? In other words,
why not have the user email us?
Reverse, reverse
Here’s what the ordinary email verification process looks like, as an interaction flow between
a handful of the components and entities involved:
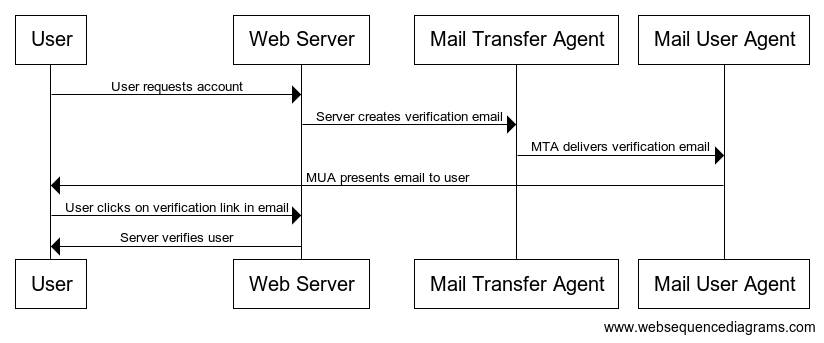
…and here’s what my proposed flow looks like:
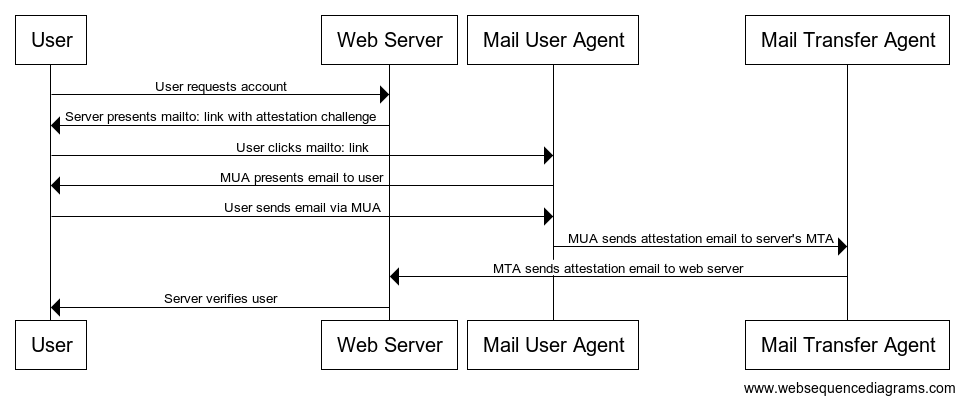
Flow diagrams aren’t the most intuitive, so as a plain sequence of steps:
- Click “new account”,
- Enter an email,
- Click on the “verify my email” link, which opens up your email client with a pre-defined
recipient, subject and body,
- Click “send”,
- Wait for the server to receive and verify it, making your account fully usable.
This has, in my eyes, a number of tangible benefits over the “normal” email verification flow:
-
The user is more active: instead of waiting to receive an email in their inbox,
the user is immediately presented with an email to send. They can make progress
in the flow themselves, and can sanity-check the state of the verification
by e.g. confirming that the email is in their outbox. Even if the flows take
roughly the same amount of wall time, this activity makes the “reverse” flow feel
faster and more responsive.
-
The user has fewer opportunities to make mistakes: Users frequently mis-copy
verification links, or use clients that mangle them, &c. These mistakes can’t
happen in the “reverse” flow, because there’s no verification link to click.
The user only has to remember how to send an email, which is a reasonable expectation
in any scheme where the user is expected to have an email address.
-
The user’s mistakes are easier to detect: If a user mis-enters their email
address in the “normal” flow, they have no easy way to determine whether
the verification email went to the wrong inbox or is simply delayed.
The reverse flow can preempt this, by embedding a private, unique ID with each challenge
email: if a received email has the ID but the wrong address, the web server can warn the user
that they’ve provided the wrong address (and can display both without leaking information,
since they’ve demonstrated knowledge of the wrong address and proved ownership
of the correct one).
How does it work (securely)?
The “reverse” flow should make intuitive sense: we’re proving that the user controls the
specified email address by challenging them to send us an email from it. This is
in contrast to the normal flow, where our proof involves sending the user an email
and challenging them to click the link contained within it. In both cases, the proof is the same:
“email verification” means “the user controls an email address.”
So: how can we be confident that the reverse flow is at least as correct and secure
as the normal flow? We need to impose several constraints.
Sending an email is not good enough
Email is notoriously spoofable: relays historically accepted messages from anybody,
with no mechanism for distinguishing authentic senders from spoofed ones.
This is made worse by SMTP’s decoupling of envelope and presentation information
for senders: an SMTP client specifies a return path address at the envelope layer
via with MAIL FROM command, and subsequently specifies one or more presentation
(i.e., email metadata) layer response addresses.
Email providers realized that this wasn’t great, and have adopted three different
(and separately scoped) standards for ensuring email authenticity:
-
DKIM
provides message body authenticity: the body of the message (including most,
but not all, presentation headers) is cryptographically signed and included in a
separate header.
Clients can then verify the DKIM signature by reading the header and generating
a subdomain from the domain and selector fields. For example, this DKIM header:
1
2
3
4
5
6
| DKIM-Signature: v=1; a=rsa-sha256; c=relaxed/relaxed;
d=yossarian.net; s=google;
h=content-transfer-encoding:content-disposition:mime-version
:message-id:subject:to:from:date:from:to:cc;
bh=<A LONG HASH HERE>;
b=<A LONG SIGNATURE HERE>
|
Results in a TXT record lookup to google._domainkey.yossarian.net, yielding
the following (slightly reformatted):
1
2
3
4
5
6
7
8
9
| v=DKIM1;
k=rsa;
p=MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEA0nbJGUQvluGxi/
P2HBPlqbzAqcaHQ2lHqGFsWp6uyX+/I2zADlp65pspYu5+Pn5yHIew4msE
YRVCzLunYfChWxDBLl5c03myhL91qRlw07jtBb/AA3F32LrILgl/IE2tG2
qvB8/tp9JFJB38Q6a6xFLvvYw+jqNTD50n4vcy5XHN30TWKaxx5AQxCmoL
RBAzMAxB6zqWoEPAYjSKrT2pIXwobvJy48C5JqXuDXCMu/7VeV7Gvt/7P6
CtWYoBbEuwSOl4bmYUQgfr0Q/Jhkjbn5QaJ1iUa6yjQrzFBOd8rzc7zLXG
RgRiPTxmpyYMJm9tUSthgOrmfWA6D4QpBb//dwIDAQAB
|
…which we can then use to verify the b=... signature provided in the header.
But note! This only authenticates the body of the email, not the envelope.
For that, we’ll need another standard.
-
SPF is the
counterpart to DKIM: where DKIM provides email body authenticity, SPF provides
email envelope authenticity.
SPF’s mode of operation is conceptually similar, using DNS as the fundamental
distribution and authority mechanism: the email’s Return-Path header
(which is directly copied from the envelope) is parsed for the underlying
domain, which is then queried for an SPF record. For example,
here’s the one on my domain:
1
| v=spf1 include:_spf.google.com ~all
|
SPF records describe sender policies, which boil down to rules that
either accept or reject the message based on the sender’s IP address.
Mine is a little indirect; it says to reuse (via the include: directive)
Google’s SPF rules, and reject everything else (~all).
We can tunnel into them, and see that they’re recursive:
1
2
3
4
| $ dig +short _spf.google.com TXT
> "v=spf1 include:_netblocks.google.com include:_netblocks2.google.com include:_netblocks3.google.com ~all"
$ dig +short _netblocks.google.com TXT
> "v=spf1 ip4:35.190.247.0/24 ip4:64.233.160.0/19 ip4:66.102.0.0/20 ip4:66.249.80.0/20 ip4:72.14.192.0/18 ip4:74.125.0.0/16 ip4:108.177.8.0/21 ip4:173.194.0.0/16 ip4:209.85.128.0/17 ip4:216.58.192.0/19 ip4:216.239.32.0/19 ~all"
|
…and so, in effect: if the IP address that sent the email matches one of the
IPs derived from the SPF policy, then the email is accepted. If it doesn’t,
then it’s rejected.
Another important note: unlike DKIM, SPF is just DNS. There is no
cryptographic authenticity or integrity; just cold, hard DNS records.
-
DMARC is the odd one out: it’s not
an authentication scheme like DKIM or SPF, but a scheme management scheme
that wraps DKIM and SPF together into a single policy, which
can then be further configured to tell clients how they should verify
a particular domain’s mail.
DMARC exists because of a historical decision in the design and rollout
of DKIM and SPF: because DKIM and SPF were designed to be retrofitted into
the pre-existing email network, clients default to “failing open” when DKIM
or SPF authenticity information isn’t available.
In other words: without an additional layer, all an attacker needs to do to
is remove the DKIM or SPF metadata from the email message. No metadata means
that the client assumes no checks, and lets the message through without
complaint.
DMARC’s solution is yet another round of DNS TXT records, this time
establishing that DKIM and SPF do apply to a particular domain, and what
the client should do with the message if either one (or both) fail to pass.
DKIM “fixes” the fail-open behavior by mandating that clients check the DMARC
record (if present), rather than only checking DNS records if the message
itself indicates a need.
Because nothing in the world of email is consistent, DMARC records use a
third different subdomain scheme for its TXT records:
1
2
| $ dig +short _dmarc.google.com TXT
> "v=DMARC1; p=reject; rua=mailto:mailauth-reports@google.com"
|
Put together, these three standards represent the best commonly deployed
email authenticity techniques. As such, they’re what we need to use for
our “reverse” flow. Anything else would require users (and email providers)
to make changes to accommodate us, which simply isn’t going to happen.
As for how we’d use them: we need SPF to provide envelope authenticity (i.e.,
ensuring that the IP that sends us an email is authorized to do so by the
domain that it’s claiming to be from), and DKIM to provide message authenticity
(i.e., that the header and body of the email are signed with key specified
by the domain specified in the DKIM header.) Without these, we could not be
confident that (1) the email is coming from the server(s) we expect, and (2)
that the body of the email has not been tampered with by an intermediary.
I don’t think this scheme needs DMARC, since we don’t want the sending
email server to have any control over our enforcement of SPF and DKIM policies:
anything other than perfect SPF and DKIM availability and correctness must
result in a failure.
Session and uniqueness considerations
On top of the (relatively weak) authenticity guarantees that DKIM and SPF provide
provide, this scheme needs a couple of other components:
-
A unique token: the mailto: challenge must include a sufficiently
long and random number. This will prevent the user from attempting to manually
initiate the flow without some amount of context on the server side,
and will prevent the (unlikely) error case where two users who both control
an email inbox attempt to register at the same time.
-
A timeout: the mailto: challenge should not be indefinitely valid.
The server should expect a response within a reasonable window, like 10
minutes. This will limit the exposure risk of accidentally leaking or
sharing the mailto: challenge.
Is it a good idea?
I have no idea; it just popped into my head. I think it’s more user-friendly,
and I’m pretty sure it’s at least as secure as the “normal” flow:
-
Completing the flow is equivalent to proving that you control an email address,
which is the same as the proof in the “normal” flow.
-
The combination of SPF and DKIM ensure the authenticity of the email’s
envelope and body (respectively), preventing spoofing.
-
The intermediate steps of the flow are not sensitive to a passive attacker:
the mailto: challenge cannot be used or manipulated by an attacker who doesn’t
control the email account.
I could be convinced that it’s an unacceptable abuse of SPF and relies on a
historically fragile URI scheme (mailto:), but my current perception is that
the use of SPF here is more-or-less appropriate (and consistent with its intended use)
and that the mailto: features required (recipient, subject, and body) are
well-supported by the overwhelming majority of email clients. It’s a shame that
SPF isn’t cryptographically bound in any way but, well, neither is DNS itself
(and you’re certainly relying on that being correct to faithfully deliver your
verification emails).
Some potential limitations and other thoughts:
-
It’s possible that a significant fraction of the Internet is
either self-hosting email servers or is otherwise using providers that don’t
support SPF and DKIM. I’m not aware of any large providers that don’t,
but it’s possible and would need to be evaluated.
-
Do websites currently allow verification emails to raw IPs? I would expect
them not to but, if they do, this would be a source of some incompatibility
for the “reverse” flow (since DNS is absolutely required for SPF and DKIM).
This could be “fixed” with a special case for email addresses on raw IPs,
where the IP in the email address is checked directly against the address that
submits the challenge verification email. But that’s not ideal.
-
As Matthew Green has pointed out,
DKIM is not really intended for this (it’s only meant to provide origin authenticity,
not nonrepudiation/nondeniability, much less ownership of a specific identity).
In an ideal world, Google and other email providers would (1) use strong DKIM
keys by default, and (2) periodically rotate and disclose their
secret keys, ensuring deniability for leaked emails. I think this shouldn’t
pose a risk to the scheme I’ve proposed, since the timescale in question is
minutes and not days (much less weeks or years).
-
Outbound SMTP connections are occasionally blocked on public WiFi, meaning
that users who use non-webmail clients may find it difficult to send the
challenge response email. I’ve only seen this a handful of times and each
had other problems (like blocking SMTP and IMAP entirely), which means
that the “normal” flow was similarly broken.
Discussions:
Reddit
Twitter