
Aug 10, 2021 Tags: llvm, rust Series: llvm-internals
This post is at least a year old.
Previously: LLVM internals, part 1.
In the last post, I performed a high-level overview of LLVM’s bitcode format (and underlying bitstream container representation). The end result of that post was a release announcement for llvm-bitcursor, which provides the critical first abstraction(s) for a pure-Rust bitcode parser.
This post will be a more concrete walkthrough of the process of parsing actual LLVM bitstreams, motivated by another release announcement: llvm-bitstream.
Put together, the llvm-bitcursor and llvm-bitstream crates get us two thirds-ish
of the way to a pure-Rust parser for LLVM IR. The only remaining major
component is a “mapper” from the block and record representations in the
bitstream to actual IR-level representations (corresponding to llvm::Module,
llvm::Function, &c in the official C++ API).
To quickly recap: LLVM’s bitstream format has two kinds of entities: blocks and records. Blocks provide a basic amount of state required to parse their constituent records (and sub-blocks); records are self-contained sequences of fields. At the bitstream level, the fields of a record are just unsigned integers1.
Every of block is identified by a “block ID” that’s globally unique (i.e., globally defined for the kind of bitstream being parsed), while every record is identified by a “record code” that’s only unique to the kind of block that the record is found in2.
Neither blocks nor records are byte-aligned (hence the “bit” in bitstream), and neither is guaranteed to have a consistent size within a given bitstream: the emitter is allowed to vary its use of variable-bit integers for compression purposes, and consumers are expected to handle this.
Every entity in a bitstream (records and blocks!) has an abbreviation ID, which tells the parser exactly how it should go about parsing the entity that immediately follows the ID. The abbreviation ID falls into one of two groups (reserved or defined), which can be modeled with the following pretty Rust enums:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
/// Abbreviation IDs that are reserved by LLVM.
#[repr(u64)]
pub enum ReservedAbbrevId {
/// Identifies an `END_BLOCK` record.
EndBlock = 0,
/// Identifies an `ENTER_SUBBLOCK` record.
EnterSubBlock,
/// Identifies a `DEFINE_ABBREV` record.
DefineAbbrev,
/// Identifies an `UNABBREV_RECORD` record.
UnabbrevRecord,
}
/// An abbreviation ID, whether reserved or defined by the stream itself.
pub enum AbbrevId {
/// A reserved abbreviation ID.
Reserved(ReservedAbbrevId),
/// An abbreviation ID that's been defined within the stream.
Defined(u64),
}
Reserved abbreviation IDs can be thought of as “bootstrapping” markers —
they provide the minimal amount of structure required for scoping
(ENTER_SUBBLOCK and END_BLOCK) and record definition (DEFINE_ABBREV and
UNABBREV_RECORD). DEFINE_ABBREV in particular is where the “bootstrapping”
analogy shines through: it signals an “abbreviation definition” record that
results in a defined abbreviation ID for a particular scope. More on record
formatting and scoping rules in a moment.
To successfully and correctly parse an LLVM bitstream, we need to handle three discrete aspects of the container format:
Let’s do each, one-by-one.
As mentioned above: all records start with an abbreviation ID. More concretely,
all records start with either UNABBREV_RECORD (i.e., ID 3) or a defined
abbreviation ID that refers back to a DEFINE_ABBREV record that applies
to the scope that the record is in.
UNABBREV_RECORDs are called unabbreviated records, while all others are
abbreviated records (since, as above, their format is defined by an abbreviation
definition elsewhere in the stream). Unabbreviated records are simpler, so we’ll
start with them.
The UNABBREV_RECORD format is an inefficient, general purpose format for
contexts where custom record definitions would be overly complicated or would
not yield meaningful size improvements (such as within the BLOCKINFO block).
Records in the UNABBREV_RECORD format look like this:
1
[code:VBR6, numops:VBR6, op0:VBR6, op1:VBR6, ...]
(Here and below: the :VBR<N> and :<N> suffixes indicate variable-width and
fixed-width integers, respectively. See the LLVM documentation and the
previous post for more details on VBRs.)
To tie it together:
numops, we read another 6-bit VBR; this is
the actual field value for this particular operand.By way of example, consider the following string representation of an UNABBREV_RECORD:
1
[0b000100, 0b000011, 0b010000, 0b011111, 0b000001, 0b100000]
This defines a new record of code 4 (0b000100) with three fields:
0: 16 (0b010000)1: 31 (0b011111)2: 32 ([0b000001, 0b100000])Note that field 2 is 12 bits instead of 6, since the value 32 isn’t representable
in a single VBR6 block!
DEFINE_ABBREV and abbreviated recordsNow that we know how to parse unabbreviated records, let’s move into the heart of the bitstream: abbreviation definitions and records that are abbreviated using them.
As mentioned in the last post, LLVM’s bitstream container is fundamentally a
self-describing format: emitters are strongly encouraged to use
DEFINE_ABBREV to produce compact bitstreams instead of relying on the more
general, less compact UNABBREV_RECORD encoding.
To parse an abbreviated record, we need to get its corresponding
abbreviation definition, i.e. the appropriately scoped DEFINE_ABBREV that defines
the structure we’re about to parse. The actual scoping rules for acquiring
this DEFINE_ABBREV are described immediately below, so we’ll just assume
them for this section.
Once we actually have the DEFINE_ABBREV, it looks like this:
1
[numabbrevops:VBR5, abbrevop0, abbrevop1, ...]
Looks a lot like the UNABBREV_RECORD structure above! Some salient differences:
DEFINE_ABBREV doesn’t specify a standalone field for the record code. Instead,
the first abbreviation operand specifies the record code.
Abbreviation operands are not concrete fields: they’re symbolic operands
that tell the bitstream parser how to parse the actual fields of a concrete
record that uses this DEFINE_ABBREV for its structure.
An appropriate analogy here is structure definition versus declaring any particular
instance of a structure: where UNABBREV_RECORD is a self-describing format,
any abbreviated record requires a reference back to its DEFINE_ABBREV for
correct parsing.
Parsing the abbreviation operands happens in a loop over numabbrevops, just
like with UNABBREV_RECORD. Each operand has the following bit-form:
1
[encoded:1, ...]
…where encoded is a 1-bit field that indicates whether the operand is “encoded”.
When encoded is 1, the operand is a “literal” operand of the following form:
1
[litvalue:VBR8]
“Literal” operands are the exception to the conceptual “concrete vs symbolic”
rule from earlier3: when a DEFINE_ABBREV has a literal operand,
that operand’s record field has the same value in all records that use the
same abbreviation. The obvious application of this is record codes, since we
expect most records that share an abbreviation to have the same code. However,
LLVM doesn’t actually enforce that only the first operand can be literal (or
must be literal), so there’s nothing stopping a bitstream emitter from
using literals for other record fields.
By contrast, when encoded is 0, the parser elaborates into one of the
following forms:
1
2
[encoding:3]
[encoding:3, value:VBR5]
The elaborated form is determined by the value of encoding, chiefly:
1) and VBR (2): [encoding:3, value: VBR5]
value indicates “extra data” needed for the parse:
for Fixed value indicates the number of bits to read for a fixed-width
value, while for VBR it indicates the number of bits to read per VBR block.3), Char6 (4), Blob (5): [encoding:3]
[a-zA-Z0-9-_] space to the
numerals 0..63. LLVM presumably does this as a terse encoding for
identifiers, when identifiers can be safely normalized as Latin
alphanumeric strings.[count:VBR6, <align32bits>, b0:8, b1:8, ..., <align32bits>].
There can only be one Blob operand per DEFINE_ABBREV, and it must be
the last operand in the operand list.DEFINE_ABBREV. Unlike Blob, Array must be second-to-last
in the operand list. To complete its parse, Array steals the last operand
in the list and uses it as its element type. Not all operands are valid
element types for Array; in particular, only Fixed, VBR, and Char6
are valid. This (fortunately) means that nested arrays and arrays-of-blobs
cannot be naively represented in the bitstream format4.Note that encoding forms 0, 6, and 7 are not defined. LLVM could
presumably add new encodings in a future release, but current parsers should
probably error on encountering these5.
When fully parsed, each DEFINE_ABBREV tells us exactly how to parse
any abbreviated record that uses it. For example, consider the following
symbolic DEFINE_ABBREV:
1
[DEFINE_ABBREV, 0b00010, 0b1, 0b00001000, 0b0, 0b010, 0b01110]
Broken down:
0b00010)
0b1) of value 8 (0b00001000)
86.0b0) of form VBR (2, 0b010)
0b01110), so our VBR is a VBR14. Any concrete field that we parse for
this this operand will be parsed as a VBR14.To understand how this DEFINE_ABBREV relates to an actual abbreviated record,
let’s assume that its abbreviation ID is 16 and that the current abbreviation
ID width is 6. Then, the following bitstring:
1
[0b010000, 0b00000011111111]
Parses as:
0b010000 maps to our DEFINE_ABBREV.Literal(8);VBR(14); parse 0b00000011111111 (0xff).Record(code: 8, fields: [0x8, 0xff]).…which amounts to just 20 bits per record in the trivial case, instead of
over 24 bits in the UNABBREV_RECORD form7.
DEFINE_ABBREV and abbreviated records are complicated! But most of the
complexity is in the concept, not the implementation: under the hood, they use
the exact same primitives (VBRs and fixed-width fields) as the rest of the
bitstream. The only complexity is in the indirection.
BLOCKINFOWhen talking about abbreviation definitions, I glazed over an important detail: actually mapping a defined abbreviation ID to its corresponding abbreviation definition. This is where the bitstream’s scoping rules come into play.
In short, the abbreviation ID that determines which DEFINE_ABBREV an
abbreviated record is mapped to is calculated as follows:
4 (i.e., the
first application-defined abbreviation ID).DEFINE_ABBREVs registered to it via BLOCKINFO, we
start with those. For example, if a new block with ID 17 has three
DEFINE_ABBREVs in the BLOCKINFO, those DEFINE_ABBREVs become
abbreviation IDs 4, 5, and 6, respectively.DEFINE_ABBREVs that occur in the block itself. These
are only registered after any BLOCKINFO definitions.The only other scoping rule is scope closure: the abbreviations (and abbreviation IDs) defined for a block are only applicable in exactly that block — neither its parent nor its children can use the same abbreviation definition list. In other words: each block must compute its own set of effective abbreviation definitions (and their IDs).
Oh, but wait: there’s one slightly ugly exception: BLOCKINFO itself. When in
BLOCKINFO, DEFINE_ABBREV does not apply to the BLOCKINFO block itself;
instead, it applies to whichever block ID was last set by the special SETBID
record. This means that we have to use a little state machine to collect
the abbreviation definitions provided by a BLOCKINFO block:
(There are other records in the BLOCKINFO block, but SETBID and
DEFINE_ABBREV are the only ones currently needed for correct bitstream
parsing.)
Now that we know how to interpret individual records and appropriately associate abbreviation definitions with abbreviated record forms, we can think about the overarching task of actually parsing an entire bitstream.
While working on my own bitstream parser, I found it useful to think of the bitstream as a state machine with 3 pieces of top-level internal state:
C into the underlying bitstream;S, which contains all information pertinent to the current
block/out-of-block scope:
S.top.abbrev_width);S.top.block_id) (or None if we’ve just started the parse);BLOCKINFO block currently refers to
(S.top.blockinfo_block_id) (or None if we’re not in the BLOCKINFO
block);S.top.abbrevs).B of block_id -> [abbrev_definition], which contains all
BLOCKINFO-defined abbreviation definitions encountered so far.Given this state, we can define the initialization mechanism for the bitstream parser:
Before our first parse, push an initial scope onto S:
1
{ abbrev_width: 2, block_id: None, blockinfo_block_id: None, abbrevs: [] }
Advance C by S.top.abbrev_width bits. The resulting value is the first abbreviation ID,
and must be a ENTER_SUBBBLOCK; any other ID represents an invalid state.
Use the ENTER_SUBBBLOCK format to populate a new scope, and push it onto S:
1
[blockid:VBR8, newabbrevlen:VBR4, <align32bits>, blocklen:32]
In particular, the new scope contains:
1
{ abbrev_width: newabbrevlen, block_id: Some(blockid), blockinfo_block_id: None, abbrevs: [] }
Then, the primary advancement mechanism:
Fill the S.top.abbrevs for the current scope with any abbreviation
definitions that match S.top.block_id in B.
If we are in a BLOCKINFO block, use the BLOCKINFO-specific state machine
to (further) populate B8.
Advance by S.top.abbrev_width:
If our next entry is a record, parse it with the appropriate strategy (abbreviated or unabbreviated). Go to 3.
If our next entry is a new block (ENTER_SUBBLOCK), populate a new scope and push it onto S as we do in the initialization phase. Go to 1.
If our next entry is a block end (END_BLOCK), pop the current scope top. Go to 3.
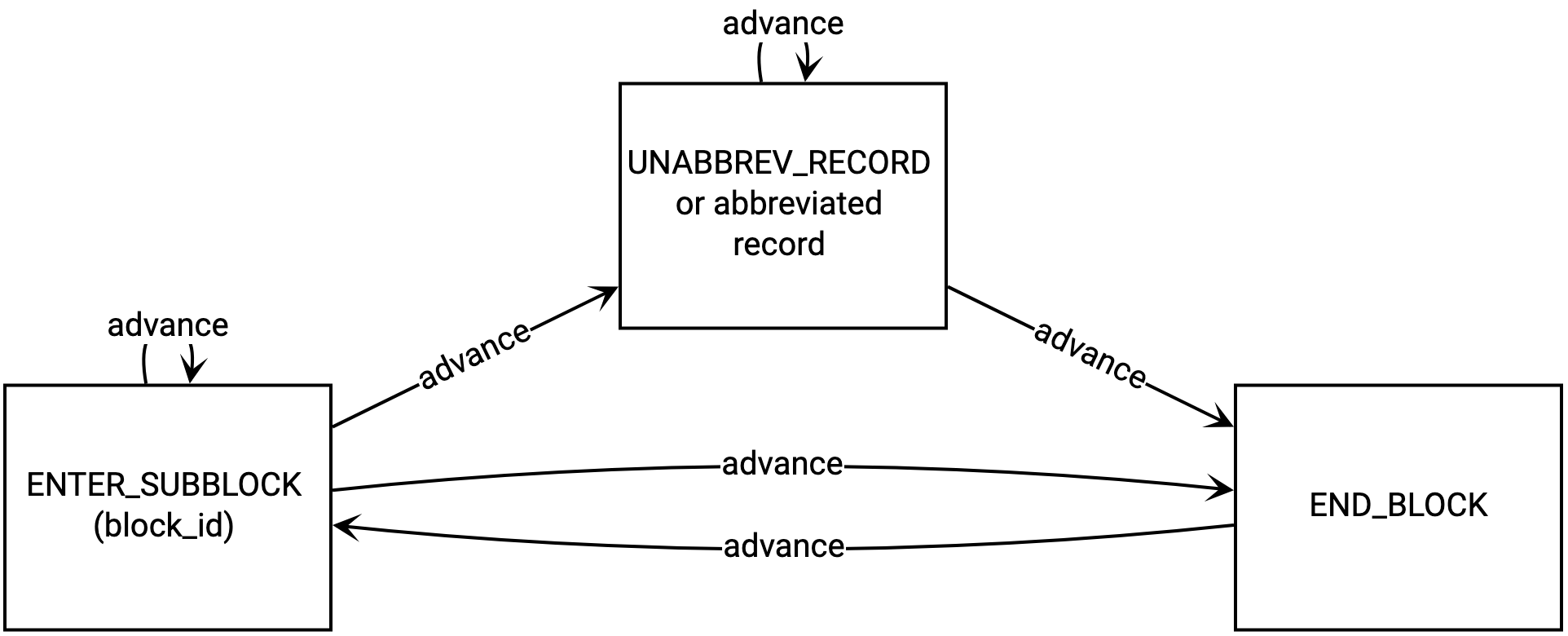
Visualized, roughly (ignoring scope state management and BLOCKINFO):
Here’s where I talk about the actual implementation.
To the best of my knowledge, it’s only the third LLVM bitstream
parser publicly available, and only the second implementation that’s entirely
independent from the LLVM codebase (the other being Galois’s
llvm-pretty-bc-parser)9.
I’ve done all of the above in a new Rust library: llvm-bitstream.
You can try it out today by building the dump-bitstream example program that
it comes with:
1
2
3
$ git clone https://github.com/woodruffw/mollusc && cd mollusc
$ cargo build --examples
$ cargo run --example dump-bitstream some-input.bc
Yields something like this (excerpted):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Entered bitstream; magic: 0xDEC04342
BLOCK 13 {
RECORD { code: 1, values: [Array([Char6(37), Char6(37), Char6(47), Char6(38), Char6(53), Char6(52), Char6(62), Char6(52), Char6(62), Char6(52)])] }
RECORD { code: 2, values: [Unsigned(0)] }
}
BLOCK 8 {
RECORD { code: 1, values: [Unsigned(2)] }
BLOCK 17 {
RECORD { code: 1, values: [Unsigned(6)] }
RECORD { code: 7, values: [Unsigned(32)] }
RECORD { code: 21, values: [Unsigned(0), Array([Unsigned(0), Unsigned(0), Unsigned(0)])] }
RECORD { code: 8, values: [Unsigned(1), Unsigned(0)] }
RECORD { code: 16, values: [] }
RECORD { code: 8, values: [Unsigned(0), Unsigned(0)] }
RECORD { code: 2, values: [] }
}
... snip ...
The output isn’t very pretty or useful at the moment, but it demonstrates full
consumption of the stream itself, including internal interpretation of the
BLOCKINFO block and abbreviation handling. Those parse details aren’t
surfaced to the public API, meaning that users don’t need to worry about them
when consuming a bitstream — all blocks and records appear above their
extra bit representation, preventing any accidental dependencies on particular
layout decisions made by a bitstream emitter. All in only about 600 lines of Rust!
From here, there’s a great deal of work to be done:
The records emitted by llvm-bitstream are fundamentally content- and context-agnostic, meaning that they don’t themselves understand what they are (a function, a basic block, &c). To get to that, yet another still-higher-level library is required, one that will map individual bitstream blocks and records onto concrete, specialized structures for individual features in LLVM’s IR.
Similarly other, non-IR features in the bitstream will need to be mapped. These include other top-level bitstream blocks that contain important metadata, debug information, and string tables.
Testing. LLVM’s IR is massive, and there are probably less-documented edge cases that I’ve failed to consider. Apart from unit tests for individual parser features, two comprehensive testing strategies stand out as reasonable:
Equivalence tests against the output of
llvm-bcanalyzer --dump,
which emits a pseudo-XML format that should be easy to replicate.
Smoke tests against random LLVM IR that’s been generated by
llvm-stress
and converted into a bitstream with llvm-as.
Up next: each of the above. Be on the lookout for another post in this series, probably next month!
This isn’t exactly true, since abbreviated records specify higher level semantic and structural information (such as when a particular field is a Char6 instead of a 6-bit fixed-width integer). But this is effectively unnecessary for writing a correct bitstream parser; it only tells us a bit more about the eventual expected record structure. ↩
Put another way: block ID #8 always refers to the same “kind” of block within a particular bitstream, but record code #4 will refer to a different kind of record depending on the ID of the enclosing block. ↩
One of several places where LLVM’s bitstream format is conceptually very dense, for arguably little gain. ↩
Another of these places where the bitstream format is very complicated. Why do array operands “steal” their following operand, instead of using another encoding form that embeds the operand itself? I assume the LLVM developers had a good reason for doing this, but it confused the bejeezus out of me when writing my parser. ↩
A good example: it’d be great if signed VBRs had their own encoding code, since this would make their use in records actually self-describing rather than a matter of knowing that a particular record code in a particular block happens to use them instead of “normal” VBRs. As-is, the code that will eventually be responsible for mapping to IR objects will need to special-case these. But again, I’m sure there’s a good historical or engineering reason why the bitstream format doesn’t include this. ↩
Which, again, is context-specific: a code of 8 means something in one block ID, and another thing in another block ID. ↩
The UNABBREV_RECORD form would be 6 bits for the code, 6 for the operand count, and then multiple 6-bit VBR blocks for each concrete operand (since we can’t use the optimal 14-bit VBR form). In the naive case we’d expect this to be around 24 to 30 bits per record, depending on the value distribution. ↩
As far as I can tell, there’s no rule against a bitstream having multiple BLOCKINFO blocks. I can’t think of any reason why you’d want that, but it doesn’t seem to be forbidden and has well-ish defined semantics (abbreviations would presumably be inserted in visitation order). ↩
I would have loved to use this implementation as a cross-reference, but my Haskell is nowhere near good enough. ↩