
Dec 16, 2020 Tags: c, curiosity, programming, security, x86
This post is at least a year old.
I was reading the Linux 5.10 release summary on KernelNewbies, and a section stood out to me:
1.6. Static calls for improved post-Spectre performance
Static calls are a replacement for global function pointers. They use code patching to allow direct calls to be used instead of indirect calls. They give the flexibility of function pointers, but with improved performance. This is especially important for cases where retpolines would otherwise be used, as retpolines can significantly impact performance.
I’ve spent a lot of time looking at the Linux kernel, but never directly at its indirect call setup or post-Spectre mitigations. These changes sound very cool, so I’m going to use this post to try and explain and understand them (both to myself and others).
Update: One of the original authors of the patchset has emailed me with some corrections and answers to the questions that I ask below. I’ve marked each with either “Correction” or “Update.” Thanks, Peter!
Indirect calls are one of C’s most powerful language features, and are critical for writing higher-order code without a supplementary object or function/method dispatch system.
Most C programmers are familiar with the basics of indirect calls, thanks to standard and POSIX
functions like qsort and pthread_create: each takes a function pointer, which it then
calls internally to complete the functionality of the surrounding call:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
/* qsort_strcmp is just the normal stdlib strcmp, with a bit of extra parameter
* munging to match qsort's API.
*/
static int qsort_strcmp(const void *a, const void *b) {
return strcmp(*(const char **)a, *(const char **)b);
}
int main(void) {
const char *strings[] = {"foo", "bar", "baz"};
/* qsort is a generic sorting function:
* you give it the a pointer to the base address of things to sort,
* their number and individual sizes, and a *function* that can compare
* any two members and provide an ordering between them.
*
* in this case, we tell qsort to sort an array of strings, using
* `qsort_strcmp` for the ordering.
*/
qsort(&strings, 3, sizeof(char *), qsort_strcmp);
printf("%s %s %s\n", strings[0], strings[1], strings[2]);
return 0;
}
(View it on Godbolt).
In this case, the indirect call occurs within qsort. But we can see it directly if
we implement our own function that does an indirect call:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
static uint32_t good_rand() {
uint32_t x;
getrandom(&x, sizeof(x), GRND_NONBLOCK);
return x;
}
static uint32_t bad_rand() {
return rand();
}
/* munge takes a function pointer, rand_func, which it calls
* as part of its returned result.
*/
static uint32_t munge(uint32_t (*rand_func)(void)) {
return rand_func() & 0xFF;
}
int main(void) {
uint32_t x = munge(good_rand);
uint32_t y = munge(bad_rand);
printf("%ul, %ul\n", x, y);
return 0;
}
where munge boils down to:
1
2
3
4
5
6
7
8
9
10
munge:
push rbp
mov rbp, rsp
sub rsp, 16
mov qword ptr [rbp - 8], rdi ; load rand_func
call qword ptr [rbp - 8] ; call rand_func
and eax, 255
add rsp, 16
pop rbp
ret
(View it on Godbolt).
Observe: our call goes through a memory or register operand ([rbp - 8])1 to get the target,
instead of a direct target specified by the operand value itself (like, say,
call 0xacabacab ; @good_rand). That’s what makes it indirect.
But we can go even further than this! Indeed, a common pattern in C is to declare entire structures of operations, using each to parametrize a lower level set of behaviors (for example, the core POSIX I/O APIs) over independent implementations.
This is exactly how FUSE works: every FUSE client
creates its own fuse_operations:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
struct fuse_operations {
int (*getattr) (const char *, struct stat *, struct fuse_file_info *fi);
int (*readlink) (const char *, char *, size_t);
int (*mknod) (const char *, mode_t, dev_t);
int (*mkdir) (const char *, mode_t);
int (*unlink) (const char *);
int (*rmdir) (const char *);
int (*symlink) (const char *, const char *);
int (*rename) (const char *, const char *, unsigned int flags);
int (*link) (const char *, const char *);
/* ... */
int (*open) (const char *, struct fuse_file_info *);
int (*read) (const char *, char *, size_t, off_t,
struct fuse_file_info *);
int (*write) (const char *, const char *, size_t, off_t,
struct fuse_file_info *);
int (*statfs) (const char *, struct statvfs *);
/* ... */
}
Unsurprisingly, this technique isn’t limited to userspace: the Linux kernel itself makes
aggressive use of indirect calls, particularly in architecture-agnostic interfaces
(like the VFS and sub-specializations
like procfs) and the architecture-specific internals of subsystems like
perf_events.
So that’s neat. It’s so neat that CPU engineers got all hot in the pants trying to squeeze extra performance out of them2, and we ended up with Spectre v2.
The exact mechanism that Spectre v2 (also known as CVE-2017-5715) exploits is slightly out of scope of this post, but at a high level:
Modern (x86) CPUs contain an indirect branch predictor, which attempts to guess the target of an indirect call or jump.
To actually speed things up, the CPU speculatively executes the predicted branch:
A correct prediction means that the indirect call completes significantly faster (since it’s already executing or has finished executing speculatively);
A misprediction should result in a slower (but still successful) indirect call with no side effects from the incorrect speculation.
In other words: the CPU is responsible for rolling back any side effects associated with any misprediction and subsequent speculation. Mis-speculation is a microarchitectural detail that should not manifest in architectural changes, like modified registers.
Rolling back any mis-speculated state is a relatively expensive operation, with a lot of microarchitectural implications: cache lines and other bits of state need to be fixed up so that the actual program control flow isn’t tainted by failed speculations.
In practice, rolling back the entire speculated state would undo most of the advantages of speculating in the first place. Instead of doing that, x86 and other ISAs will just mark (many) of the bits of speculated state (like cache lines) as stale.
This fixup behavior (either reverting or marking speculated state) results in a side-channel: an attacker can train the branch predictor to speculatively execute a bit of code (not unlike a ROP gadget) that modifies a piece of microarchitectural state in a data-dependent manner, such as a cache entry whose address is dependent on a secret value that was speculatively fetched.
The attacker can then probe that microarchitectural state by timing access to it: fast accesses indicate a speculatively modified state, disclosing the secret.
The original Spectre v2 attack focused on cache lines since they’re relatively easy to time, even
from high level (and sandboxed!) languages that don’t have access to
clflush or other cache-line
primitives on x86. But the concept is a general one: it’s difficult to execute speculatively without
leaking some information, and subsequent vulnerabilities (like MDS and
ZombieLoad) have exposed information leaks in other
microarchitectural features.
This is bad news: an attacker running one of the safest contexts (JavaScript or other managed code, in a sandbox, in userspace) can conceivably train the indirect branch predictor to speculatively execute a gadget in kernelspace, potentially disclosing kernel memory.
So, the kernel needed a new mitigation. That mitigation is retpolines.
To mitigate Spectre v2, the kernel needs to prevent the CPU from speculating on an attacker controlled indirect branch.
A retpoline (short for return trampoline) does exactly that: indirect jumps and calls are surrounded by a little thunk that effectively traps the speculated execution in an infinite loop, spinning it until the misprediction is resolved.
Intel’s Retpoline whitepaper has some helpful illustrations:
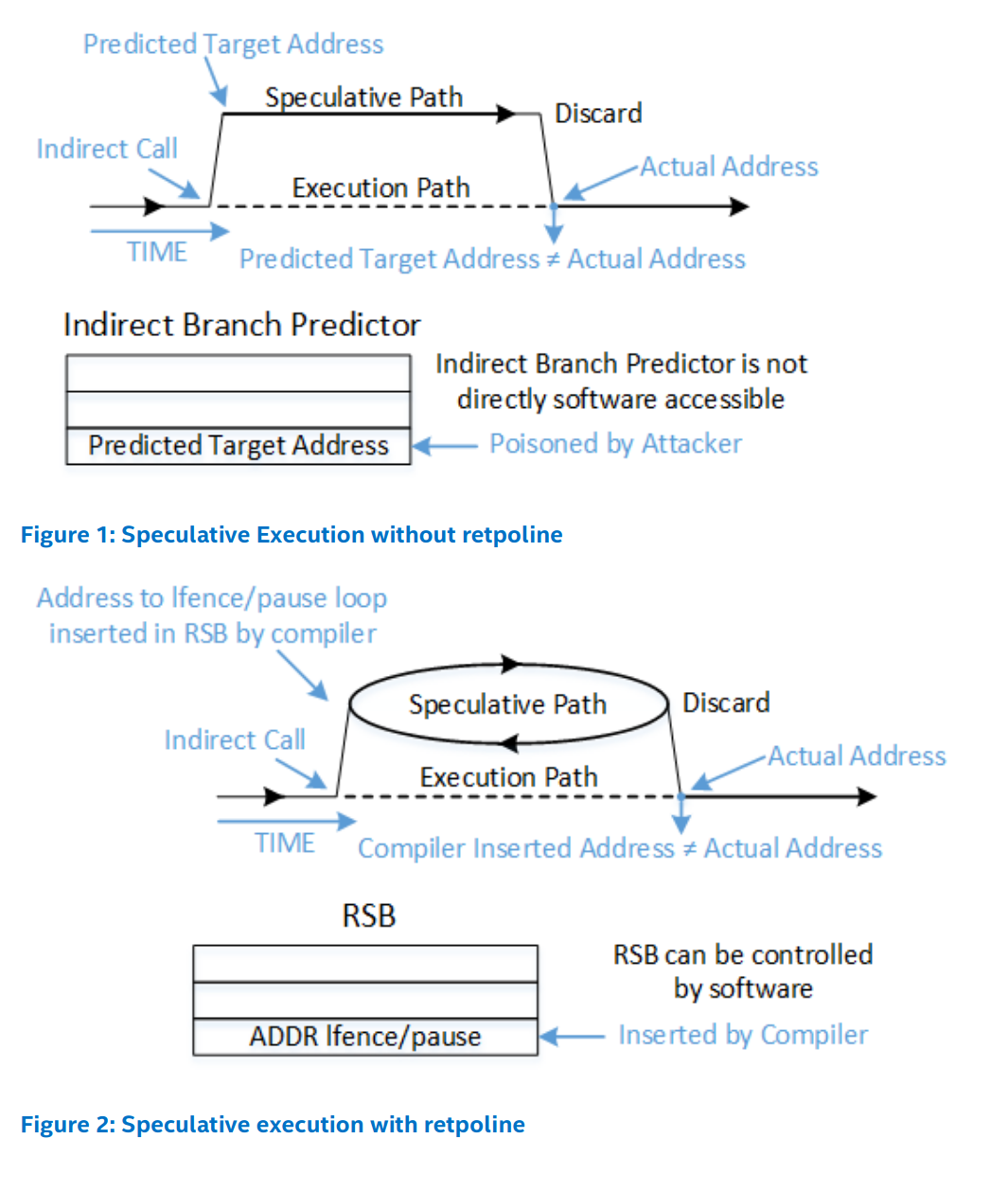
This works by converting the indirect control flow from an indirect branch to an
indirect return3, hence the “ret” in retpoline. Returns are also predicted,
but with an additional mechanism given priority: the
Return Stack Buffer4. To ensure that
the RSB can’t be maliciously trained away from the infinite loop, the retpoline begins with a
direct CALL that primes the RSB to always5 predict the infinite loop.
Here’s what an indirect call retpoline actually looks like6, simplified significantly from the kernel source:
1
2
3
4
5
6
7
8
9
__x86_retpoline_rax:
call .Ldo_rop_0
.Lspec_trap_0:
pause
lfence
jmp .Lspec_trap_0
.Ldo_rop_0:
mov [rsp], rax
ret
…all of that to replace a simple call [rax]!
There are repercussions for this kind of trickery:
It’s slow when correctly predicted: we’ve replaced a single indirect CALL with at least two
direct CALLs, plus a RET.
It’s really slow when mispredicted: we literally spin in place using PAUSE and LFENCE.
It’s a ROP gadget, so it looks like an exploit primitive. That means it screws with Intel’s CET and similar protections on other platforms. Intel claims that newer hardware will support “enhanced IBRS”7 that will replace the need for retpolines entirely, allowing CET to be used.
It’s just plain hard to read and follow, even when stripped down like above: the complete mitigation also needs to handle indirect jumps, RSB stuffing, and a whole swarm of other tricks that people have found since the original Spectre v2.
Let’s see what Linux 5.10 has done to remove some of this pain.
Let’s check out this new “static call” technique. Here’s the API, direct from the Josh Poimboeuf’s patch series:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
/* declare or define a new static call as `name`,
* initially associated with `func`
*/
DECLARE_STATIC_CALL(name, func);
DEFINE_STATIC_CALL(name, func);
/* invoke `name` with `args` */
static_call(name)(args...);
/* invoke `name` with `args` if not NULL */
static_call_cond(name)(args...);
/* update the underlying function */
static_call_update(name, func);
and an (abbreviated and annotated) example in perf, pulled from the same series:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
static void _x86_pmu_add(struct perf_event *event) { }
/* ... */
DEFINE_STATIC_CALL(x86_pmu_add, _x86_pmu_add);
static void x86_pmu_static_call_update(void) {
/* ... */
static_call_update(x86_pmu_add, x86_pmu.add);
/* ... */
}
static int __init init_hw_perf_events(void) {
/* ... */
x86_pmu_static_call_update();
/* ... */
}
To summarize:
An empty static function, _x86_pmu_add, is defined.
DEFINE_STATIC_CALL is used on _x86_pmu_add, giving it the name x86_pmu_add.
A helper function, x86_pmu_static_call_update, is defined.
static_call_update to modify x86_pmu_add’s underlying function
(_x86_pmu_add), replacing it with x86_pmu.add (a function pointer)Finally, our __init function (init_hw_perf_events) calls the static call helper.
As a result, a call that was previously:
1
2
3
if (x86_pmu.add) {
x86_pmu.add(event);
}
is now:
1
static_call_cond(x86_pmu_add)(event);
That’s pretty clean, and it (apparently) avoids the need for the retpoline! Let’s find out why and how.
Using x86_pmu_add as our guinea pig:
DEFINE_STATIC_CALLOn x86, DEFINE_STATIC_CALL(x86_pmu_add, _x86_pmu_add) expands roughly to this:
1
2
3
4
5
6
7
8
extern struct static_call_key __SCK__x86_pmu_add;
extern typeof(_x86_pmu_add) __SCT__x86_pmu_add_tramp;
struct static_call_key __SCK__x86_pmu_add = {
.func = _x86_pmu_add,
};
ARCH_DEFINE_STATIC_CALL_TRAMP(x86_pmu_add, _x86_pmu_add);
What about
ARCH_DEFINE_STATIC_CALL_TRAMP?
1
2
3
4
5
6
7
8
9
10
11
12
#define __ARCH_DEFINE_STATIC_CALL_TRAMP(name, insns) \
asm(".pushsection .static_call.text, \"ax\" \n" \
".align 4 \n" \
".globl " STATIC_CALL_TRAMP_STR(name) " \n" \
STATIC_CALL_TRAMP_STR(name) ": \n" \
insns " \n" \
".type " STATIC_CALL_TRAMP_STR(name) ", @function \n" \
".size " STATIC_CALL_TRAMP_STR(name) ", . - " STATIC_CALL_TRAMP_STR(name) " \n" \
".popsection \n")
#define ARCH_DEFINE_STATIC_CALL_TRAMP(name, func) \
__ARCH_DEFINE_STATIC_CALL_TRAMP(name, ".byte 0xe9; .long " #func " - (. + 4)")

Sigh. That expands (with reformatting) to:
1
2
3
4
5
6
7
8
9
.pushsection .static_call.text, "ax"
.align 4
.globl "__SCT__x86_pmu_add_tramp"
"__SCT__x86_pmu_add_tramp":
.byte 0xe9
.long _x86_pmu_add - (. + 4)
.type "__SCT__x86_pmu_add_tramp", @function
.size "__SCT__x86_pmu_add_tramp", . - "__SCT__x86_pmu_add_tramp"
.popsection
What’s .byte 0xe9? It’s a relative JMP!
Specifically, it’s a JMP to the address calculated by .long _x86_pmu_add - (. + 4), which is
ugly GAS syntax for “the address of _x86_pmu_add, minus the current address
(indicated by .), plus 4”.
Why the arithmetic? It’s a relative JMP, so the destination needs to be made relative to the
RIP immediately following the JMP itself. The JMP is 1 byte but we’re using .align 4,
so . + 4 ensures that we subtract both the current location and fix up the JMP and
padding8.
Correction: It turns out I overthought this: the JMP is 5 bytes (1 byte opcode, 4 bytes)
displacement, so . + 4 gets us to the RIP immediately after the entire instruction. It
has nothing to do with alignment.
So that’s just the setup for our static call. Let’s see how we actually install a
function with static_call_update.
static_call_update.Here’s how static_call_update(x86_pmu_add, x86_pmu.add) breaks down:
1
2
3
4
({
BUILD_BUG_ON(!__same_type(*(x86_pmu.add), __SCT__x86_pmu_add_tramp));
__static_call_update(&__SCK__x86_pmu_add, &__SCT__x86_pmu_add_tramp, x86_pmu.add);
})
We’re just going to ignore BUILD_BUG_ON and __same_type, since they’re a compile-time sanity
check. Check out this SO post for BUILD_BUG_ON; it’s
fun9.
Let’s look at __static_call_update:
1
2
3
4
5
6
7
static inline
void __static_call_update(struct static_call_key *key, void *tramp, void *func) {
cpus_read_lock();
WRITE_ONCE(key->func, func);
arch_static_call_transform(NULL, tramp, func, false);
cpus_read_unlock();
}
The fun never ends!
First things first: we’re just going to skip cpus_read_lock and cpus_read_unlock, since they do
exactly what they say on the tin.
Here’s WRITE_ONCE:
1
2
3
4
5
6
7
8
9
10
#define __WRITE_ONCE(x, val) \
do { \
*(volatile typeof(x) *)&(x) = (val); \
} while (0)
#define WRITE_ONCE(x, val) \
do { \
compiletime_assert_rwonce_type(x); \
__WRITE_ONCE(x, val); \
} while (0)
So, it’s really just a volatile-qualified assign for types that are atomic10:
1
*(volatile (void *) *)&((&__SCK__x86_pmu_add)->func) = x86_pmu.add;
(I think I got that right.)11
Now for arch_static_call_transform:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
void arch_static_call_transform(void *site, void *tramp, void *func, bool tail)
{
mutex_lock(&text_mutex);
if (tramp) {
__static_call_validate(tramp, true);
__static_call_transform(tramp, __sc_insn(!func, true), func);
}
if (IS_ENABLED(CONFIG_HAVE_STATIC_CALL_INLINE) && site) {
__static_call_validate(site, tail);
__static_call_transform(site, __sc_insn(!func, tail), func);
}
mutex_unlock(&text_mutex);
}
More things to ignore:
mutex_lock and mutex_unlock are just here to make sure nobody else
is patching the kernel’s instruction text. We’re simultaneously inside of cpus_read_lock, which
(I presume) is preventing someone else from reading in the middle of our patch.
Correction: cpus_read_lock doesn’t actually block a read — it serializes us against
a CPU hotplug or removal. TIL!
I’m not going to talk about CONFIG_HAVE_STATIC_CALL_INLINE at all in this post. It’s very
similar to the normal static call mechanism, but with a lot more moving parts. So we’ll just
act as if that config is false and that code isn’t compiled in.
A thing to not ignore:
__sc_insn maps two booleans, func and tail, to an insn_type enum. Two booleans means two
bits, which means four possible insn_type states:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
enum insn_type {
CALL = 0, /* site call */
NOP = 1, /* site cond-call */
JMP = 2, /* tramp / site tail-call */
RET = 3, /* tramp / site cond-tail-call */
};
static inline enum insn_type __sc_insn(bool null, bool tail)
{
/*
* Encode the following table without branches:
*
* tail null insn
* -----+-------+------
* 0 | 0 | CALL
* 0 | 1 | NOP
* 1 | 0 | JMP
* 1 | 1 | RET
*/
return 2*tail + null;
}
This will be on the test.
That brings us to __static_call_validate which (you guessed it) validates
our trampoline:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
static void __static_call_validate(void *insn, bool tail)
{
u8 opcode = *(u8 *)insn;
if (tail) {
if (opcode == JMP32_INSN_OPCODE ||
opcode == RET_INSN_OPCODE)
return;
} else {
if (opcode == CALL_INSN_OPCODE ||
!memcmp(insn, ideal_nops[NOP_ATOMIC5], 5))
return;
}
/*
* If we ever trigger this, our text is corrupt, we'll probably not live long.
*/
WARN_ONCE(1, "unexpected static_call insn opcode 0x%x at %pS\n", opcode, insn);
}
Remember: tail is always true for us, since we’re not CONFIG_HAVE_STATIC_CALL_INLINE.
So insn is always tramp which, you’ll recall, is __SCT__x86_pmu_add_tramp with
its cute little .byte 0xe9.
Finally, __static_call_transform (condensed slightly) is where the real magic happens:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
static void __ref __static_call_transform(void *insn, enum insn_type type, void *func)
{
int size = CALL_INSN_SIZE;
const void *code;
switch (type) {
case CALL:
code = text_gen_insn(CALL_INSN_OPCODE, insn, func);
break;
case NOP:
code = ideal_nops[NOP_ATOMIC5];
break;
case JMP:
code = text_gen_insn(JMP32_INSN_OPCODE, insn, func);
break;
case RET:
code = text_gen_insn(RET_INSN_OPCODE, insn, func);
size = RET_INSN_SIZE;
break;
}
if (memcmp(insn, code, size) == 0)
return;
if (unlikely(system_state == SYSTEM_BOOTING))
return text_poke_early(insn, code, size);
text_poke_bp(insn, code, size, NULL);
}
Remember __sc_insn (I told you to!): tail is always true for us, so our only options
are (1, 0) and (1, 1), i.e. JMP and RET. This (again) will matter in a little bit, but
the code for both cases is nearly identical so we can ignore the difference.
In both cases we call
text_gen_insn,
which is the world’s simplest JIT12 (condensed a bit):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
union text_poke_insn {
u8 text[POKE_MAX_OPCODE_SIZE];
struct {
u8 opcode;
s32 disp;
} __attribute__((packed));
};
static __always_inline
void *text_gen_insn(u8 opcode, const void *addr, const void *dest)
{
static union text_poke_insn insn; /* per instance */
int size = text_opcode_size(opcode);
insn.opcode = opcode;
if (size > 1) {
insn.disp = (long)dest - (long)(addr + size);
if (size == 2) {
BUG_ON((insn.disp >> 31) != (insn.disp >> 7));
}
}
return &insn.text;
}
So, our dest (i.e., x86_pmu.add) becomes our relative displacement, just like in our
compile-time-generated thunk.
The rest is mechanics: we call either text_poke_early or text_poke_bp based on the system
state, but the effect is the same: our trampoline (__SCT__x86_pmu_add_tramp) is
effectively rewritten in kernel memory from:
1
jmp _x86_pmu_add
to:
1
jmp x86_pmu.add
…or any other function we desire, types permitting!
static_call_condFinally, let’s figure out how we actually call this damn thing.
Our actual invocation is static_call_cond(x86_pmu_add)(event) which, as the name implies,
should do a check before dispatching to the underlying trampoline, right?
1
2
#define static_call(name) __static_call(name)
#define static_call_cond(name) (void)__static_call(name)

Nope! Recall that little __sc_insn table generator again: if our underlying call is NULL,
we’ve already generated and JITted a little RET into our trampoline.
Let’s see what our
__static_call
actually expands to:
1
2
3
4
({
__ADDRESSABLE(__SCK__x86_pmu_add);
&__SCT__x86_pmu_add_tramp;
})
(__ADDRESSABLE is just another bit of compiler trickery to ensure that __SCK__x86_pmu_add
sticks around in the symbol table).
That’s everything: our actual static_call boils down to a call to __SCT__x86_pmu_add_tramp,
which is either a trampoline that bounces us to the real call or just a RET, completing the
call.
In other words, the assembly looks like one of two cases:
1
2
3
4
5
call __SCT__x86_pmu_add_tramp
; in call + trampoline
jmp x86_pmu.add
; out of trampoline, in target (x86_pmu.add)
; target eventually returns, completing the call
or:
1
2
3
call __SCK__x86_pmu_add
; in call + "trampoline"
ret ; "trampoline" returns, completing the call
And who said that kernel code was hard to follow13?
This post ended up being way longer than I originally intended, in part because I ended up going further into the why of static calls more than I planned.
Some observations:
I’ve always generally understood how speculative execution vulnerabilities work, but I hadn’t bothered to actually read the Spectre whitepaper before. It’s a lot simpler than I expected! Same goes for retpolines.
This implementation is information dense and full of advanced macro use, but it isn’t actually all that complicated: diligently expanding the macros by hand got me 95% of the way there, with the rest being code comprehension and cross-referencing with Elixir. I’ve done a decent bit of kernel development before, but this has given me a newfound appreciation for the Linux kernel’s layout and paradigms.
I didn’t even try to cover CONFIG_HAVE_STATIC_CALL_INLINE, which makes up a significant
percentage of this changeset by linecount. It’s an even more aggressive transformation: instead
of rewriting the trampoline, every callsite that would have called the trampoline is rewritten
to make a direct call to the trampoline’s target. This saves a single JMP14, which is
apparently enough of a performance difference to be worth a separate configurable feature.
Update: Peter Zijlstra has explained that the performance advantage of
CONFIG_HAVE_STATIC_CALL_INLINE comes primarily from decreased instruction cache pressure:
because the trampoline is unconditional the CPU will always prefetch it, taking up a cache line.
Avoiding that fetch yields measurable performance improvements!
I’m not sure what WRITE_ONCE(__SCK__x86_pmu_add->func, x86_pmu.add) actually accomplishes: it
stores a copy of the function pointer in our static_call_key, which we then never actually use
(since we always call the trampoline, which has the relative displacement of the function patched
directly into it). Calling this pointer would defeat that entire purpose of static calls,
since it’d be an indirect branch. Educated guess: it’s just there for the !CONFIG_HAVE_STATIC_CALL
case, which uses a generic, indirect implementation. But why not get rid of static_call_key
entirely when we have a real static call implementation available?
Update: Peter has also explained this: it’s only strictly useful for the
!CONFIG_HAVE_STATIC_CALL case. In particular, it prevents the compiler from
tearing the store15
into multiple stores.
I think there’s room for improvement here, particularly loosening some of the locking
requirements: the maximum text patch size is hardcoded at POKE_MAX_OPCODE_SIZE == 5, which
should fit comfortably into an atomic write on x86_64 using WRITE_ONCE16. In other words:
I’m not sure why cpus_read_lock and a lock on the text are required, although maybe I’m
underthinking it.
Update: Apparently this was considered during review. The problem: it introduces alignment
requirements, which in turn require NOPs to be injected into the instruction stream. That
in turn increases instruction cache pressure, defeating the performance advantage. There was
also some concern about underspecification by Intel and AMD for this.
The fact that the Linux kernel is self-modifying and employs a rudimentary instruction encoder is a testament to the importance of high-fidelity instruction encoding and decoding. This is a point that I’ve made with mishegos before, but to repeat it: bugs in instruction encoding/decoding are now a part of the hot paths of kernels and JITs, not just disassembly and reverse engineering tools.
Observe that there’s a missed optimization here: [rbp - 8] is just rdi, i.e. the first argument to munge. Clang optimizes this to a register-indirect call rdi with -O1, saving us a memory fetch. ↩
Indirect calls are slower than direct calls by necessity, at least on x86: they require (slightly) more pre-call setup than a normal CALL. They can also result in less-than-optimal code at compile time, since they aren’t (easily) inlinable and are more challenging to model for code size and performance optimizations. ↩
That’s right: our Spectre v2 mitigation is itself a ROP gadget. ↩
Which, as you might have guessed, is its own source of speculative vulnerabilities! See here, here, and here. ↩
Not really: this is a microarchitectural detail, and Intel’s Skylake family in particular can be tricked into using the indirect branch predictor by emptying the RSB. See “Empty RSB Mitigation on Skylake-generation” in Intel’s retpoline whitepaper. ↩
Specifically, this is an “out-of-line” construction that plays well with relocatable code. It’s nearly identical to the one Google offers here, which probably isn’t a coincidence. ↩
“Indirect Branch Restricted Speculation” ↩
This took me about 10 minutes to figure out. I didn’t notice the .align 4 originally and was driving myself crazy trying to justify it. ↩
__same_type, by comparison, is surprisingly boring: it’s just a wrapper for GCC’s __builtin_types_compatible_p. ↩
Or maybe not: compiletime_assert_rwonce_type allows 64-bit reads and writes on 32-bit hosts, relying on “a strong prevailing wind”. ↩
Why void *? Because Because x is static_call_key.func, which is void *. No trickery there. ↩
I’m sure I’m going to annoy someone by calling it a JIT. Mentally replace “JIT” with “Self-modifying code” if you need to. ↩
This was very hard for me to follow. ↩
And maybe more? I didn’t read this part of the code closely. ↩
This was the first time I’d heard of “store-tearing.” Turns out it’s the same as store-splitting, i.e. breaking a particular store op into smaller constituent ops (and thereby potentially erasing some serialization, visibility, or consistency guarantee). ↩
Or maybe a slightly modified version, since poking the .text requires us to twiddle CR0 first. Maybe that’s the reason for the extra locking. Correction: Apparently text_poke_bp doesn’t actually twiddle cr0 at all! There’s some “ungodly magic” at play that I’ll have to look into. ↩