 “multi-pass” — Leeloo Dallas
“multi-pass” — Leeloo DallasOct 23, 2020 Tags: llvm, programming
This post is at least a year old.
With thanks to Niki Carroll, winny, and kurufu for their invaluable proofreading and advice.
By popular demand, I’m doing another LLVM post. This time, it’s single static assignment (or SSA) form, a common feature in the intermediate representations of optimizing compilers.
Like the last one, SSA is a topic in compiler and IR design that I mostly understand but could benefit from some self-guided education on. So here we are.
At the highest level, a compiler’s job is singular: to turn some source language input into some machine language output. Internally, this breaks down into a sequence of clearly delineated1 tasks:
In a single-pass compiler, (4) is monolithic: machine code is generated as the compiler walks the AST, with no revisiting of previously generated code. This is extremely fast (in terms of compiler performance) in exchange for some a few significant limitations:
Optimization potential: because machine code is generated in a single pass, it can’t be revisited for optimizations. Single-pass compilers tend to generate extremely slow and conservative machine code.
By way of example: the
System V ABI
(used by Linux and macOS) defines
a special 128-byte region beyond the
current stack pointer (%rsp) that can be used by leaf functions whose stack frames fit within
it. This, in turn, saves a few stack management instructions in the function prologue and
epilogue.
A single-pass compiler will struggle to take advantage of this ABI-supplied optimization: it needs to emit a stack slot for each automatic variable as they’re visited, and cannot revisit its function prologue for erasure if all variables fit within the red zone.
Language limitations: single-pass compilers struggle with common language design decisions, like allowing use of identifiers before their declaration or definition. For example, the following is valid C++:
1
2
3
4
5
6
class Rect {
public:
int area() { return width() * height(); }
int width() { return 5; }
int height() { return 5; }
};
C and C++ generally require pre-declaration and/or definition for identifiers, but
member function bodies may reference the entire class scope. This will frustrate a
single-pass compiler, which expects Rect::width and Rect::height to already exist
in some symbol lookup table for call generation.
Consequently, (virtually) all modern compilers are multi-pass.
“multi-pass” — Leeloo Dallas
Multi-pass compilers break the translation phase down even more:
So, we want an IR that’s easy to correctly transform and that’s amenable to optimization. Let’s talk about why IRs that have the static single assignment property fill that niche.
At its core, the SSA form of any program source program introduces only one new constraint: all variables are assigned (i.e., stored to) exactly once.
By way of example: the following (not actually very helpful) function is not in a valid SSA form
with respect to the flags variable:
1
2
3
4
5
6
7
8
9
10
11
int helpful_open(char *fname) {
int flags = O_RDWR;
if (!access(fname, F_OK)) {
flags |= O_CREAT;
}
int fd = open(fname, flags, 0644);
return fd;
}
Why? Because flags is stored to twice: once for initialization, and (potentially) again inside
the conditional body.
As programmers, we could rewrite helpful_open to only ever store once to each automatic variable:
1
2
3
4
5
6
7
8
9
int helpful_open(char *fname) {
if (!access(fname, F_OK)) {
int flags = O_RDWR | O_CREAT;
return open(fname, flags, 0644);
} else {
int flags = O_RDWR;
return open(fname, flags, 0644);
}
}
But this is clumsy and repetitive: we essentially need to duplicate every chain of uses that follow any variable that is stored to more than once. That’s not great for readability, maintainability, or code size.
So, we do what we always do: make the compiler do the hard work for us. Fortunately there exists a transformation from every valid program into an equivalent SSA form, conditioned on two simple rules.
Rule #1: Whenever we see a store to an already-stored variable, we replace it with a brand new “version” of that variable.
Using rule #1 and the example above, we can rewrite flags using _N suffixes to indicate versions:
1
2
3
4
5
6
7
8
9
10
11
12
13
int helpful_open(char *fname) {
int flags_0 = O_RDWR;
// Declared up here to avoid dealing with C scopes.
int flags_1;
if (!access(fname, F_OK)) {
flags_1 = flags_0 | O_CREAT;
}
int fd = open(fname, flags_1, 0644);
return fd;
}
But wait a second: we’ve made a mistake!
open(..., flags_1, ...) is incorrect: it unconditionally assigns O_CREAT, which wasn’t in the
original function semantics.open(..., flags_0, ...) is also incorrect: it never assigns O_CREAT, and thus
is wrong for the same reason.So, what do we do? We use rule 2!
Rule #2: Whenever we need to choose a variable based on control flow, we use the Phi function (φ) to introduce a new variable based on our choice.
Using our example once more:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
int helpful_open(char *fname) {
int flags_0 = O_RDWR;
// Declared up here to avoid dealing with C scopes.
int flags_1;
if (!access(fname, F_OK)) {
flags_1 = flags_0 | O_CREAT;
}
int flags_2 = φ(flags_0, flags_1);
int fd = open(fname, flags_2, 0644);
return fd;
}
Our quandary is resolved: open always takes flags_2, where flags_2 is a fresh SSA variable
produced applying φ to flags_0 and flags_1.
Observe, too, that φ is a symbolic function: compilers that use SSA forms internally do not emit real φ functions in generated code5. φ exists solely to reconcile rule #1 with the existence of control flow.
As such, it’s a little bit silly to talk about SSA forms with C examples (since C and other high-level languages are what we’re translating from in the first place). Let’s dive into how LLVM’s IR actually represents them.
First of all, let’s see what happens when we run our very first helpful_open through clang
with no optimizations:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
define dso_local i32 @helpful_open(i8* %fname) #0 {
entry:
%fname.addr = alloca i8*, align 8
%flags = alloca i32, align 4
%fd = alloca i32, align 4
store i8* %fname, i8** %fname.addr, align 8
store i32 2, i32* %flags, align 4
%0 = load i8*, i8** %fname.addr, align 8
%call = call i32 @access(i8* %0, i32 0) #4
%tobool = icmp ne i32 %call, 0
br i1 %tobool, label %if.end, label %if.then
if.then: ; preds = %entry
%1 = load i32, i32* %flags, align 4
%or = or i32 %1, 64
store i32 %or, i32* %flags, align 4
br label %if.end
if.end: ; preds = %if.then, %entry
%2 = load i8*, i8** %fname.addr, align 8
%3 = load i32, i32* %flags, align 4
%call1 = call i32 (i8*, i32, ...) @open(i8* %2, i32 %3, i32 420)
store i32 %call1, i32* %fd, align 4
%4 = load i32, i32* %fd, align 4
ret i32 %4
}
(View it on Godbolt.)
So, we call open with %3, which comes from…a load from an i32* named %flags?
Where’s the φ?
This is something that consistently slips me up when reading LLVM’s IR: only values,
not memory, are in SSA form. Because we’ve compiled with optimizations disabled, %flags is
just a stack slot that we can store into as many times as we please, and that’s exactly what
LLVM has elected to do above.
As such, LLVM’s SSA-based optimizations aren’t all that useful when passed IR that makes direct use of stack slots. We want to maximize our use of SSA variables, whenever possible, to make future optimization passes as effective as possible.
This is where mem2reg comes in:
This file (optimization pass) promotes memory references to be register references. It promotes alloca instructions which only have loads and stores as uses. An alloca is transformed by using dominator frontiers to place phi nodes, then traversing the function in depth-first order to rewrite loads and stores as appropriate. This is just the standard SSA construction algorithm to construct “pruned” SSA form.
(Parenthetical mine.)
mem2reg gets run at -O1 and higher, so let’s do exactly that:
1
2
3
4
5
6
7
8
define dso_local i32 @helpful_open(i8* nocapture readonly %fname) local_unnamed_addr #0 {
entry:
%call = call i32 @access(i8* %fname, i32 0) #4
%tobool.not = icmp eq i32 %call, 0
%spec.select = select i1 %tobool.not, i32 66, i32 2
%call1 = call i32 (i8*, i32, ...) @open(i8* %fname, i32 %spec.select, i32 420) #4, !dbg !22
ret i32 %call1, !dbg !23
}
Foiled again! Our stack slots are gone thanks to mem2reg, but LLVM has actually optimized
too far: it figured out that our flags value is wholly dependent on the return value of our
access call and erased the conditional entirely.
Instead of a φ node, we got this select:
1
%spec.select = select i1 %tobool.not, i32 66, i32 2
which the LLVM Language Reference describes concisely:
The ‘select’ instruction is used to choose one value based on a condition, without IR-level branching.
So we need a better example. Let’s do something that LLVM can’t trivially optimize into a
select (or sequence of selects), like adding an else if with a function that we’ve only
provided the declaration for:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
size_t filesize(char *);
int helpful_open(char *fname) {
int flags = O_RDWR;
if (!access(fname, F_OK)) {
flags |= O_CREAT;
} else if (filesize(fname) > 0) {
flags |= O_TRUNC;
}
int fd = open(fname, flags, 0644);
return fd;
}
produces:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
define dso_local i32 @helpful_open(i8* %fname) local_unnamed_addr #0 {
entry:
%call = call i32 @access(i8* %fname, i32 0) #5
%tobool.not = icmp eq i32 %call, 0
br i1 %tobool.not, label %if.end4, label %if.else
if.else: ; preds = %entry
%call1 = call i64 @filesize(i8* %fname) #5
%cmp.not = icmp eq i64 %call1, 0
%spec.select = select i1 %cmp.not, i32 2, i32 514
br label %if.end4
if.end4: ; preds = %if.else, %entry
%flags.0 = phi i32 [ 66, %entry ], [ %spec.select, %if.else ]
%call5 = call i32 (i8*, i32, ...) @open(i8* %fname, i32 %flags.0, i32 420) #5
ret i32 %call5
}
(View it on Godbolt.)
That’s more like it! Here’s our magical φ:
1
%flags.0 = phi i32 [ 66, %entry ], [ %spec.select, %if.else ]
LLVM’s phi is slightly more complicated than the φ(flags_0, flags_1) that I made up before, but
not by much: it takes a list of pairs (two, in this case), with each pair containing a possible
value and that value’s originating basic block (which, by construction, is always a predecessor
block in the context of the φ node).
The Language Reference backs us up:
1
<result> = phi [fast-math-flags] <ty> [ <val0>, <label0>], ...
The type of the incoming values is specified with the first type field. After this, the ‘phi’ instruction takes a list of pairs as arguments, with one pair for each predecessor basic block of the current block. Only values of first class type may be used as the value arguments to the PHI node. Only labels may be used as the label arguments.
There must be no non-phi instructions between the start of a basic block and the PHI instructions: i.e. PHI instructions must be first in a basic block.
Observe, too, that LLVM is still being clever: one of our φ choices is a computed
select (%spec.select), so LLVM still managed to partially erase the original control flow.
So that’s cool. But there’s a piece of control flow that we’ve conspicuously ignored.
What about loops?
1
2
3
4
5
6
7
int do_math(int count, int base) {
for (int i = 0; i < count; i++) {
base += base;
}
return base;
}
yields:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
define dso_local i32 @do_math(i32 %count, i32 %base) local_unnamed_addr #0 {
entry:
%cmp5 = icmp sgt i32 %count, 0
br i1 %cmp5, label %for.body, label %for.cond.cleanup
for.cond.cleanup: ; preds = %for.body, %entry
%base.addr.0.lcssa = phi i32 [ %base, %entry ], [ %add, %for.body ]
ret i32 %base.addr.0.lcssa
for.body: ; preds = %entry, %for.body
%i.07 = phi i32 [ %inc, %for.body ], [ 0, %entry ]
%base.addr.06 = phi i32 [ %add, %for.body ], [ %base, %entry ]
%add = shl nsw i32 %base.addr.06, 1
%inc = add nuw nsw i32 %i.07, 1
%exitcond.not = icmp eq i32 %inc, %count
br i1 %exitcond.not, label %for.cond.cleanup, label %for.body, !llvm.loop !26
}
Not one, not two, but three φs! In order of appearance:
Because we supply the loop bounds via count, LLVM has no way to ensure that we actually enter
the loop body. Consequently, our very first φ selects between the initial %base and %add.
LLVM’s phi syntax helpfully tells us that %base comes from the entry block and %add from
the loop, just as we expect. I have no idea why LLVM selected such a hideous name for the resulting
value (%base.addr.0.lcssa).
Our index variable is initialized once and then updated with each for iteration, so it also
needs a φ. Our selections here are %inc (which each body computes from %i.07) and the 0
literal (i.e., our initialization value).
Finally, the heart of our loop body: we need to get base, where base is either the initial
base value (%base) or the value computed as part of the prior loop (%add). One last φ gets
us there.
The rest of the IR is bookkeeping: we need separate SSA variables to compute the addition (%add),
increment (%inc), and exit check (%exitcond.not) with each loop iteration.
(View it on Godbolt.)
So now we know what an SSA form is, and how LLVM represents them6. Why should we care?
As I briefly alluded to early in the post, it comes down to optimization potential: the SSA forms of programs are particularly suited to a number of effective optimizations.
Let’s go through a select few of them.
One of the simplest things that an optimizing compiler can do is remove code that cannot possibly be executed. This makes the resulting binary smaller (and usually faster, since more of it can fit in the instruction cache).
“Dead” code falls into several categories7, but a common one is assignments that cannot affect program behavior, like redundant initialization:
1
2
3
4
5
6
7
8
9
10
11
12
13
int main(void) {
int x = 100;
if (rand() % 2) {
x = 200;
} else if (rand() % 2) {
x = 300;
} else {
x = 400;
}
return x;
}
Without an SSA form, an optimizing compiler would need to check whether any use of x reaches
its original definition (x = 100). Tedious. In SSA form, the impossibility of that is obvious:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
int main(void) {
int x_0 = 100;
// Just ignore the scoping. Computers aren't real life.
if (rand() % 2) {
int x_1 = 200;
} else if (rand() % 2) {
int x_2 = 300;
} else {
int x_3 = 400;
}
return φ(x_1, x_2, x_3);
}
And sure enough, LLVM eliminates the initial assignment of 100 entirely:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
define dso_local i32 @main() local_unnamed_addr #0 {
entry:
%call = call i32 @rand() #3
%0 = and i32 %call, 1
%tobool.not = icmp eq i32 %0, 0
br i1 %tobool.not, label %if.else, label %if.end6
if.else: ; preds = %entry
%call1 = call i32 @rand() #3
%1 = and i32 %call1, 1
%tobool3.not = icmp eq i32 %1, 0
%. = select i1 %tobool3.not, i32 400, i32 300
br label %if.end6
if.end6: ; preds = %if.else, %entry
%x.0 = phi i32 [ 200, %entry ], [ %., %if.else ]
ret i32 %x.0
}
(View it on Godbolt.)
Compilers can also optimize a program by substituting uses of a constant variable for the constant value itself. Let’s take a look at another blob of C:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
int some_math(int x) {
int y = 7;
int z = 10;
int a;
if (rand() % 2) {
a = y + z;
} else if (rand() % 2) {
a = y + z;
} else {
a = y - z;
}
return x + a;
}
As humans, we can see that y and z are trivially assigned and never modified8. For the compiler,
however, this is a variant of the reaching definition problem from above: before it can
replace y and z with 7 and 10 respectively, it needs to make sure that y and z are never
assigned a different value.
Let’s do our SSA reduction:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
int some_math(int x) {
int y_0 = 7;
int z_0 = 10;
int a_0;
if (rand() % 2) {
int a_1 = y_0 + z_0;
} else if (rand() % 2) {
int a_2 = y_0 + z_0;
} else {
int a_3 = y_0 - z_0;
}
int a_4 = φ(a_1, a_2, a_3);
return x + a_4;
}
This is virtually identical to our original form, but with one critical difference:
the compiler can now see that every load of y and z is the original assignment. In other
words, they’re all safe to replace!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
int some_math(int x) {
int y = 7;
int z = 10;
int a_0;
if (rand() % 2) {
int a_1 = 7 + 10;
} else if (rand() % 2) {
int a_2 = 7 + 10;
} else {
int a_3 = 7 - 10;
}
int a_4 = φ(a_1, a_2, a_3);
return x + a_4;
}
So we’ve gotten rid of a few potential register operations, which is nice. But here’s the really critical part: we’ve set ourselves up for several other optimizations:
Now that we’ve propagated some of our constants, we can do some trivial
constant folding: 7 + 10 becomes 17, and so
forth.
In SSA form, it’s trivial to observe that only x and a_{1..4} can affect the program’s behavior.
So we can apply our dead code elimination from above and delete y and z entirely!
This is the real magic of an optimizing compiler: each individual optimization is simple and largely independent, but together they produce a virtuous cycle that can be repeated until gains diminish.
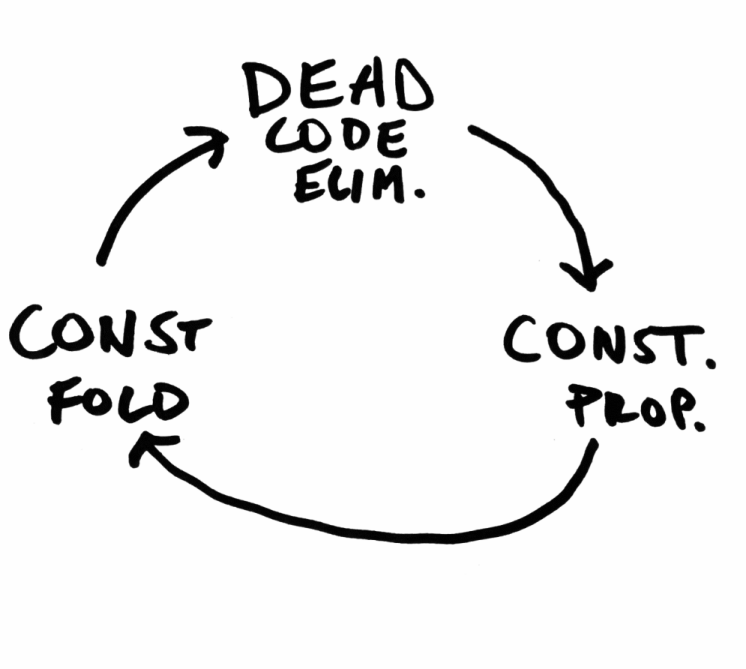 (Just one potential optimization cycle.)
(Just one potential optimization cycle.)
Register allocation (alternatively: register scheduling) is less of an optimization itself, and more of an unavoidable problem in compiler engineering: it’s fun to pretend to have access to an infinite number of addressable variables, but the compiler eventually insists that we boil our operations down to a small, fixed set of CPU registers.
The constraints and complexities of register allocation vary by architecture: x86 (prior to AMD64) is notoriously starved for registers9 (only 8 full general purpose registers, of which 6 might be usable within a function’s scope10), while RISC architectures typically employ larger numbers of registers to compensate for the lack of register-memory operations.
Just as above, reductions to SSA form have both indirect and direct advantages for the register allocator:
Indirectly: Eliminations of redundant loads and stores reduces the overall pressure on the register allocator, allowing it to avoid expensive spills (i.e., having to temporarily transfer a live register to main memory to accommodate another instruction).
Directly: Compilers have historically lowered φs into copies before register allocation, meaning that register allocators traditionally haven’t benefited from the SSA form itself11. There is, however, (semi-)recent research on direct application of SSA forms to both linear and coloring allocators1213.
A concrete example: modern JavaScript engines use JITs to accelerate program evaluation. These JITs frequently use linear register allocators for their acceptable tradeoff between register selection speed (linear, as the name suggests) and acceptable register scheduling. Converting out of SSA form is a timely operation of its own, so linear allocation on the SSA representation itself is appealing in JITs and other contexts where compile time is part of execution time.
There are many things about SSA that I didn’t cover in this post: dominance frontiers, tradeoffs between “pruned” and less optimal SSA forms, and feedback mechanisms between the SSA form of a program and the compiler’s decision to cease optimizing, among others. Each of these could be its own blog post, and maybe will be in the future!
In the sense that each task is conceptually isolated and has well-defined inputs and outputs. Individual compilers have some flexibility with respect to whether they combine or further split the tasks. ↩
The distinction between an AST and an intermediate representation is hazy: Rust converts their AST to HIR early in the compilation process, and languages can be designed to have ASTs that are amendable to analyses that would otherwise be best on an IR. ↩
This can be broken up into lexical validation (e.g. use of an undeclared identifier) and semantic validation (e.g. incorrect initialization of a type). ↩
This is what LLVM does: LLVM IR is lowered to MIR (not to be confused with Rust’s MIR), which is subsequently lowered to machine code. ↩
Not because they can’t: the SSA form of a program can be executed by evaluating φ with concrete control flow. ↩
We haven’t talked at all about minimal or pruned SSAs, and I don’t plan on doing so in this post. The TL;DR of them: naïve SSA form generation can lead to lots of unnecessary φ nodes, impeding analyses. LLVM (and GCC, and anything else that uses SSAs probably) will attempt to translate any initial SSA form into one with a minimally viable number of φs. For LLVM, this tied directly to the rest of mem2reg. ↩
Including removing code that has undefined behavior in it, since “doesn’t run at all” is a valid consequence of invoking UB. ↩
And are also function scoped, meaning that another translation unit can’t address them. ↩
x86 makes up for this by not being a load-store architecture: many instructions can pay the price of a memory round-trip in exchange for saving a register. ↩
Assuming that %esp and %ebp are being used by the compiler to manage the function’s frame. ↩
LLVM, for example, lowers all φs as one of its very first preparations for register allocation. See this 2009 LLVM Developers’ Meeting talk. ↩
Wimmer 2010a: “Linear Scan Register Allocation on SSA Form” (PDF) ↩
Hack 2005: “Towards Register Allocation for Programs in SSA-form” (PDF) ↩