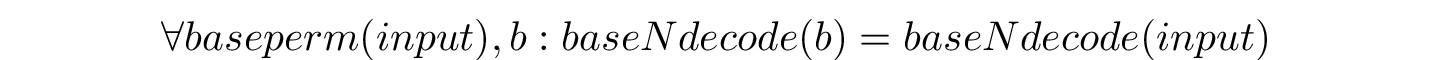
Feb 3, 2020 Tags: devblog, programming, rust
This post is at least a year old.
My first tool/library announcement for 2020 (and a rough 5 year blog anniversary, yay!):
baseperm.
baseperm is a small Rust tool: all it does is take an input in some baseN alphabet as input
(base64 and base32
are currently supported) and emit all permutations of that input that decode to the same thing as
the original input.
In other words:
Let’s go into how it works and why it exists.
baseN encoding schemes take their inputs and map them onto an alternate alphabet, usually one designed to operate in contexts where use of the full byte (or even just ASCII-printable) range would be ambiguous or interfere with the surrounding protocol.
A good example of this is SMTP, the protocol that handles email transfer between hosts. SMTP expects the session to end with a period surrounded by a pair of CRLFs, like so:
1
\r\n.\r\n
or, in hexadecimal:
1
\x13\x10\x46\x13\x10
This byte sequence could plausibly occur in a binary email attachment (or even as a typo in the main email body if using CRLF line endings), causing SMTP to prematurely hang up the connection and truncate the letter.
That would really suck, so we encode our attachments with an alphabet that can’t contain those bytes. Because that alphabet is necessarily smaller than the 8-bit (or 7-bit, if we’re just talking about ASCII) input space, encoding each byte requires more than one symbol:
| symbols | bits | bytes per symbol | |
|---|---|---|---|
| base32 | 32 | 5 | 0.625 |
| base64 | 64 | 6 | 0.75 |
| base58 | 58 | approx. 5.86 | approx. 0.73 |
As a result, not all encoded inputs are 8-bit aligned. To align things for representation as printable characters, padding bits are used: 4 bytes (32 bits) of input require 6 base64 symbols (36 bits), leaving 4 bits unused and meaningless from the perspective of the decoder.
Consequently, there are actually 16 base64 representations of a 4 byte input. For “abcd”:
YWJjZA YWJjZB YWJjZC YWJjZD YWJjZE YWJjZF YWJjZG YWJjZH YWJjZI YWJjZJ YWJjZK YWJjZL YWJjZM YWJjZN YWJjZO YWJjZP
(A small challenge: convince yourself that a zero-padded base64 encoding of any 4 bytes will
always end in one of A, Q, g, or w.)
All baseperm does is automate the discovery and output of these permutations.
Most programmers are only vaguely aware of alignment and padding considerations when encoding to an alphabet smaller than their input. Even fewer translate that awareness into the following:
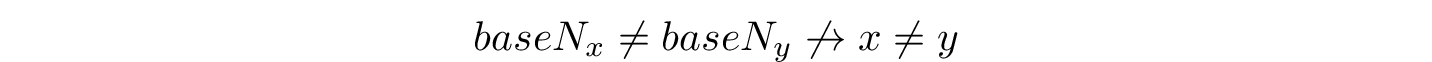
In other words: the inequality of arbitrary baseN strings does not imply the inequality of their underlying inputs — we can contrive baseN strings that are different (due to padding) that decode to the same input.
This has all sorts of interesting consequences:
Programmers who assume the above might assume that they can index on the encoded form of their input(s) for important operations: ratelimiting, maximum uses of a token, &c:
1
2
if ratelimiter.check(b64_input):
return HTTPDenied("ratelimit exceeded")
If the user can control b64_input, then they can circumvent ratelimiting here by contriving
an input that decodes correctly (for authentication/authorization purposes) but has not already
been incremented against.
Programmers who assume the above might assume properties about data structure transforms:
1
2
3
4
5
setE = {base64_a, base64_b, base64_c}
setI = {a, b, c}
setD = {base64decode(v) for v in setE}
len(setI) == len(setD)
This isn’t guaranteed to be the case: any (or all) of the encoded values here could overlap when decoded, causing the set (or dictionary, or any other structure with hash-based identity) to dedupe them.
You can get baseperm from cargo:
1
$ cargo install baseperm
Or by building it directly in the repo:
1
2
$ git clone https://github.com/woodruffw/baseperm && cd baseperm
$ cargo build
baseperm’s interface is minimal: it takes a single encoded input on stdin and
emits every permuted output on stdout, separated by newlines:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
$ echo -n "some input" | base64 | baseperm
c29tZSBpbnB1dA==
c29tZSBpbnB1dB==
c29tZSBpbnB1dC==
c29tZSBpbnB1dD==
c29tZSBpbnB1dE==
c29tZSBpbnB1dF==
c29tZSBpbnB1dG==
c29tZSBpbnB1dH==
c29tZSBpbnB1dI==
c29tZSBpbnB1dJ==
c29tZSBpbnB1dK==
c29tZSBpbnB1dL==
c29tZSBpbnB1dM==
c29tZSBpbnB1dN==
c29tZSBpbnB1dO==
c29tZSBpbnB1dP==
You can use -e, --encoding to set the encoding to something other than base64 (the default):
1
2
3
$ echo -n "another input" | base32 | baseperm -e base32
MFXG65DIMVZCA2LOOB2XI===
MFXG65DIMVZCA2LOOB2XJ===
See baseperm --help for the full list of supported encodings.