
Jul 22, 2015 Tags: data, programming, rant
This post is at least a year old.
For better or worse, the words “Internet” and “Web” are essentially synonyms to non-programmers. Though they may use protocols other than HTTP and services presented in mediums other than HTML, a gateway to those protocols and services is almost always available in the form of a good old (X)HTML website. In other words there is a lot of HTML out there of, as we will see, extremely variable quality.
“Why are HTML errors a problem?,” you might ask. “If it looks like it renders correctly, why should we care if it isn’t strictly valid?”
Well, here are some good reasons:
Incorrect HTML complicates parser and renderer implementations. Programmers have to think about the common mistakes made during HTML development/generation, and add rules to their implementations to work around them. This means wasted programmer labor, increased surface area for errors and vulnerabilities, and increased processing time and resource usage when interpreting mangled HTML.
A permissive attitude towards errors encourages web developers to rely
on the behavior of the implementation, not the standard. If “every” HTML
renderer treats a broken <a> tag the same way, developers might think it’s
acceptable to rely on this behavior to save bandwidth or when creating HTML
generators. This is the rough equivalent of justifying undefined behavior use in
C with “it works in every compiler I’ve used”.
That same permissive attitude also complicates the adoption of new standards. Because deprecated or nonsensical tags from earlier versions of HTML are often accepted by the parser even when the page specifiers a newer HTML version, developers feel safe in letting their comprehension of the newest standard lapse. At the very best, this means that HTML pages (and my bandwidth) get clogged up with attributes and tags that don’t change their structure. At the very worst, it confuses the parser and makes the already-difficult job of predicting page presentation even more difficult.
So, how bad is the situation out there?
To find out, I had to gather a list of sites to test. There’s no point in testing small-traffic sites or personal sites, as they’re more likely to be static and maintained by a single person. To see how prevalent the problem is, I had to test the sites of companies and organizations that have ample resources available to them - entire teams dedicated to their website and online presence.
With that in mind, I chose two datasets: the consumer websites of the Fortune 500, and the global top 500 sites by traffic as ranked by Alexa.
Scraping Alexa’s rankings was fairly painless, thanks to a quick script:
1
2
$ ./alexa500.rb > alexa500
$ cat alexa500 | wc -l # 500
Scraping the Fortune 500 site proved to be more trouble that it was worth, so I went with a secondary resource, which was also scraped with another quick script:
1
2
$ ./fortune500.rb > fortune500
$ cat fortune500 | wc -l # 499 - i guess we lost a duplicate
Then, a little post-processing was in order:
1
2
3
4
5
6
$ cat alexa500 fortune500 \
+ | sed -e 's/^www\.//' -e 's/\/$//' -e 's/^/http:\/\//' \ # uniformity
+ | perl -ne 'print lc' \ # lowercase each string
+ | sort | uniq > all_sites # sort and remove any duplicates
$ cat all_sites | wc -l # 981
After filtering, therefore, we’re left with 981 good sites to test against.
I was originally going to validate each site’s HTML using the W3C’s Markup Validation Service and a Perl module, but I ended up getting IP banned for “abuse” (despite not exceeding their posted rate limit).
I ended up downloading and running my own copy of the W3C’s “Nu” HTML Checker, which made scripting a bit easier:
1
2
# sends a whole mess of json to stderr
$ java -jar vnu.jar --format json http://example.com
Bundled up in another quick script:
1
$ cat all_sites | ./validate_sites.rb | tee results
Finally I had to to remove ‘unknown’ results, caused whenever vnu.jar crashed or a site timed out (both of which happened occasionally). Excluding those, I was left with 914 complete results to interpret.
Upon initial inspection, I had to eliminate a few results with extraordinarily
large error counts after realizing that these sites were sending
gzip-compressed HTML despite the lack of an Accept-encoding: header. Several
sites with fake error counts over 5000, mostly originating in China, had to be
excluded. This reduced the result count to 910.
The loser with the most real HTML errors was…
Microsoft!. At 4324 errors (not counting warnings),
Microsoft’s 415KB index.html) contained an error every 96 bytes.
Second and third place go to Whole Foods and Rakuten with 2835 and 1950 errors, respectively.
The winners were few and far between, with only 13 sites (~1.3% of the tested group) containing absolutely no errors. Among them were several fairly large sites, including google.cn (but not the main google.com), stackexchange.com and bbc.co.uk.
Some basic statistics:
Mean errors per site: 94.82
Mode errors per site: 1
Standard deviation: 253.06
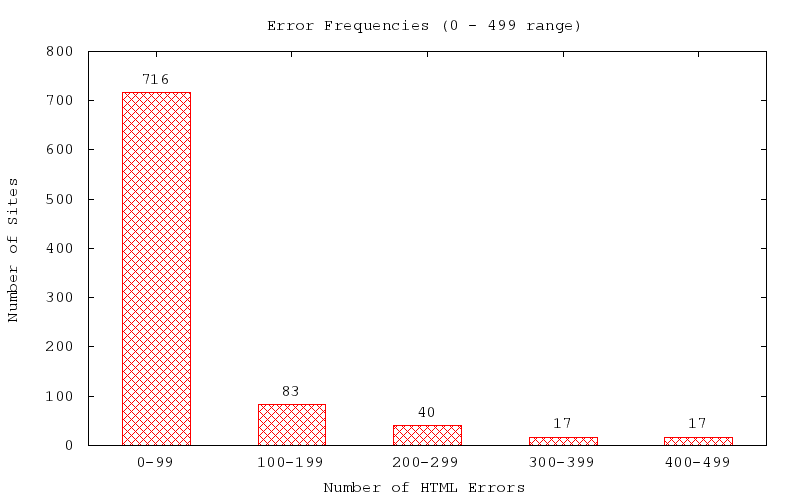
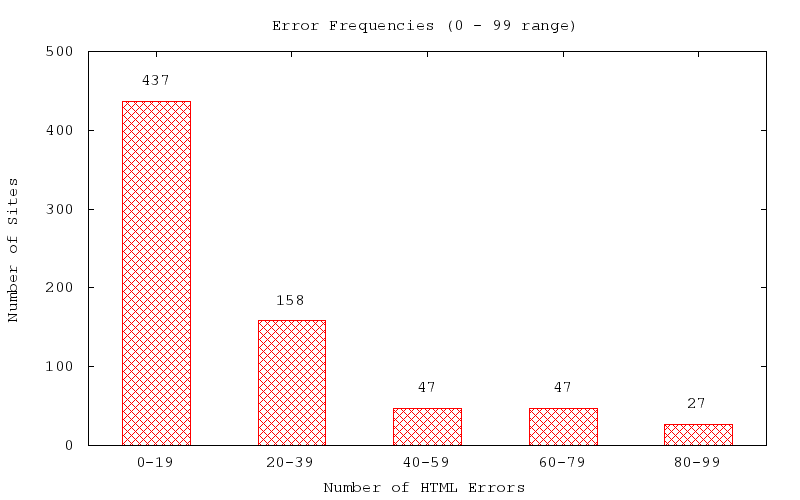
And some visualizations:
(The 9 sites with error counts greater than or equal to 1000 are not included, due to sparsity.)
I had my fair share of problems while collecting sites and data for this post.
First, I couldn’t find a good way to scrape the websites of the Fortune 500.
Then, I got IP banned from the W3C’s online validator and had difficulty
building both the old and new HTML validators from source. When I finally turned
to the Nu Validator releases, I had yet more problems with vnu.jar crashing
and attempting to decode raw gzip data without first decompressing it. All of
these things, combined with the fact that these websites are in constant flux,
make me less than certain about the relevance of the data collected.
On the other hand, I have a blog post to finish. The non-excluded data is fairly revealing in content, demonstrating that nearly half of all responding sites have at least one error (and normally a fair deal more than that). Also interesting is the small spike in sites with anywhere from 400 to 599 HTML errors, possibly suggesting a common usage of a generator with endemically faulty rules or syntax.
It’s worthwhile to note that, while I only visited a few of these sites in my actual browser, their prominence would suggest that virtually all render and display correctly on a variety of platforms in spite of any errors in markup. This is both a testament to the resiliency of HTML, and to the finesse of web engine developers everywhere. It’s also worth nothing that these numbers only indicate HTML errors, not errors in each site’s CSS and JavaScript. I am confident that a more in-depth analysis would reveal the following:
I feel like I’m repeating common sense statements here, but these kind of truisms are important to keep in mind whenever you’re the one making a new site, or even just a new page on an existing one. Your opportunity to validate your pages after generation (or even switch to a more correct generator) may seem like a waste of time, but it pays off in the long run for everybody.
If you’d like to look at the data yourself (or try your hand with a new dataset),
I’ve posted the scraping scripts above and a link to the release page for
vnu.jar. In addition,
here is a zip archive
containing the data I collected, as well as the gnuplot scripts and .dat
files used to generate the bar charts. It also includes an ad-hoc script
for interpreting the data, as well as a copy of vnu.jar.
Until next time!
- William
P.S.:
I am painfully aware of how hypocritical it is to complain about broken HTML on a blog with errors of its own. I think it’s worth noting that my blog has a single HTML error (fixable if I can be bothered), while the front-facing sites of Fortune 500 companies with entire teams dedicated to their web presence regularly have over 100.